11 Fortgeschrittene Themen
11.1 Wertelabels
Wertelabels helfen, Informationen aus dem Codebuch direkt im Datensatz abzulegen und so das arbeiten zu erleichtern. Während Stata-Datensätze häufig mit Labels geliefert werden, müssen wir bei neu erstellten Variablen diese Labels selbst erstellen.
Bspw. wenn wir aus der Altersvariable des Allbus 2018 eine neue Altersgruppen-Variable erstellen:
age_cat | Freq. Percent Cum.
------------+-----------------------------------
18 | 718 20.68 20.68
35 | 1,527 43.98 64.66
60 | 1,227 35.34 100.00
------------+-----------------------------------
Total | 3,472 100.00Um age_cat besser zu beschriften definieren wir ein Wertelabel. Dazu verwenden wir label define, gefolgt von einem Objektnamen für dieses Label (hier age_cat_lab) und dann jeweils die Ausprägungen zusammen mit dem entsprechenden label in "". Dieses Label-Objekt wenden wir dann mit label values auf die Variable age_cat an:
label define age_cat_lab 18 "18-34 Jahre" 35 "35-29 Jahre" 60 "über 60 Jahre"
label values age_cat age_cat_lab
tab age_cat age_cat | Freq. Percent Cum.
--------------+-----------------------------------
18-34 Jahre | 718 20.68 20.68
35-29 Jahre | 1,527 43.98 64.66
über 60 Jahre | 1,227 35.34 100.00
--------------+-----------------------------------
Total | 3,472 100.00Wir können außerdem mit label variable "Beschreibung" die Variable selbst beschriften, um sie so leichter auffindbar zu machen
storage display value
variable name type format label variable label
--------------------------------------------------------------------------------
age_cat double %10.0g zB. wird dieses Label mit lookfor gefunden:
storage display value
variable name type format label variable label
----------------------------------------------------------------------------------------------------
age_cat double %13.0g age_cat_lab
3er Alterseinteilung11.2 sortieren
Mit sort können wir unseren Datensatz sortieren. Dazu geben wir einfach die Variablen an, nach denen sortiert werden soll:
sort sortiert dabei immer in aufsteigenden Reihenfolge. Mit gsort können wir darüber hinaus auch in umgekehrter (fallender) Reihenfolge sortieren, indem wir - vor die entsprechende Variable stellen. Hier zb von alt nach jung, innerhalb des gleichen Alters dann aufsteigend nach Bildung und für gleich alte und gebildetet Befragte dann die Frauen (sex=2) vor den Männern (sex=1):
11.3 Informationen aus mehreren Variablen
Manchmal liegt die gewünschte Information nur aufgeteilt auf mehrere Variablen vor. Ein Beispiel hierfür ist die Alterskonstellation von (Ehe-)Paaren. Im Allbus werden sowohl das Alter der Befragten (age) als auch (ggf.) das Alter der*des Partner*in abgefragt. Zudem unterscheidet der Allbus zwischen Lebens- (page) und Ehepartner*innen (scage). Möchten wir jetzt die jeweils den Altersabstand zwischen dem Alter der männlichen und weiblichen (Ehe-)Partner berechnen1, so müssen wir durch eine Kombination aus gen und replace in mehreren Schritten vorgehen.
set linesize 120
cd ""
use "Allbus_1980-2018.dta", clear
// missings ausschließen:
replace mstat = . if mstat < 0
mvdecode *yborn, mv(-41 / -1 )
mvdecode *age, mv(-41 / -1 )
mvdecode *educ, mv(-41 / -1 )
// Alter von ihr: entweder Befragtenalter wenn sie befragt wurde oder
gen her_age = age if sex == 2
// scage wenn *er* befragt wurde und verheiratet ist -> ihr Alter ist in scage
replace her_age = scage if sex == 1 & mstat == 1
// üage *er* befragt wurde und unverheiratet ist -> ihr Alter ist in page
replace her_age = page if sex == 1 & mstat != 1
// Alter von ihm: entweder Befragtenalter wenn er befragt wurde oder
gen his_age = age if sex == 1
// scage wenn *sie* befragt wurde und verheiratet ist -> ihr Alter ist in scage
replace his_age = scage if sex == 2 & mstat == 1
// page wenn *sie* befragt wurde und verheiratet ist -> ihre Alter ist in scage
replace his_age = page if sex == 2 & mstat != 1
gen age_diff = his_age - her_age if !missing(his_age) & !missing(her_age)
su age_diff11.4 egen
egen ist die Erweiterung von gen und gibt uns die Möglichkeit, eine ganze Reihe von Berechnungen durchzuführen. Hier einige hilfreiche Befehle:
- Variable in Kategorien teilen mit
cut, hier 18 bis <29, 30 bis <60 und 60 bis <80 (Werte <18 und >80 werden zu.)
- Mittelwert über mehrere Variablen erstellen mit
rowmean, hier zum Vertrauen in staatliche Institutionen (siehed pt01 pt02 pt03 pt04 pt08 pt12 pt14)
use "Allbus2018.dta", clear
mvdecode pt01 pt02 pt03 pt04 pt08 pt12 pt14, mv(-9) // missings raus
egen trust = rowmean(pt01 pt02 pt03 pt04 pt08 pt12 pt14)Eine vollständige Liste findet sich unter help egen.
11.5 gruppierte Berechnungen
Mit dem Präfix bys können wir Berechnungen innerhalb von Gruppen durchführen. So können wir beispielsweise eine Variable erstellen, die jeweils den Mittelwert von inc für jede Altergruppe (agec) spezifischen Mittelwert enthält:
cd
use "Allbus2018.dta",clear
drop if inc < 0
drop if agec < 0
bys agec: egen mean_inc = mean(inc)
sort respid // sonst ist alles nach agec sortiert
list agec mean_inc in 1/10 +------------------------+
| agec mean_inc |
|------------------------|
1. | 60-74 JAHRE 1565.642 |
2. | 60-74 JAHRE 1565.642 |
3. | 18-29 JAHRE 1026.236 |
4. | 45-59 JAHRE 1915.664 |
5. | 30-44 JAHRE 1729.861 |
|------------------------|
6. | 30-44 JAHRE 1729.861 |
7. | 30-44 JAHRE 1729.861 |
8. | 30-44 JAHRE 1729.861 |
9. | 30-44 JAHRE 1729.861 |
10. | 60-74 JAHRE 1565.642 |
+------------------------+11.6 Subgruppen-Variablen erstellen mit separate
separate ist eine Abkürzung, um Angaben einer Variable entlang der Ausprägungen einer zweiten Variablen aufzuteilen. Das hilft uns bspw. die Aufteilung von inc nach dem Geschlecht (sex) zu vereinfachen. Wir können dies entweder mit zwei Befehlen mit gen und if durchführen oder diese zwei Schritte mit einem separate Befehl durchführen:
gen inc_m = inc if sex == 1
gen inc_f = inc if sex == 2
separate inc, by(sex)
list inc sex inc_m inc_f inc1 inc2 in 1/10(1704 missing values generated)
(1773 missing values generated)
storage display value
variable name type format label variable label
--------------------------------------------------------------------------------
inc1 int %17.0g inc inc, sex == MANN
inc2 int %17.0g inc inc, sex == FRAU +-----------------------------------------------------------+
| inc sex inc_m inc_f inc1 inc2 |
|-----------------------------------------------------------|
1. | 2200 MANN 2200 . 2200 . |
2. | 1500 FRAU . 1500 . 1500 |
3. | 1400 MANN 1400 . 1400 . |
4. | 3600 MANN 3600 . 3600 . |
5. | 1700 FRAU . 1700 . 1700 |
|-----------------------------------------------------------|
6. | 3450 MANN 3450 . 3450 . |
7. | 854 FRAU . 854 . 854 |
8. | 1500 MANN 1500 . 1500 . |
9. | KEINE ANGABE FRAU . -9 . KEINE ANGABE |
10. | 978 FRAU . 978 . 978 |
+-----------------------------------------------------------+11.7 collapse
Manchmal möchten wir vielleicht nur einen Mittelwert pro Gruppe und die einzelnen Werte interessieren uns gar nicht. Wir möchten unseren Datensatz also verkürzen, sodass er lediglich einen Wert pro Gruppe enthält. Dazu können wir mit collapse den Datensatz zusammenfassen. Wir geben dabei zunächst die gewünschte Funktion an, also z.B. mean, gefolgt von der zusammenzufassenden Variable. Wenn gewünscht können wir neuer_varname = voranstellen, um den Namen der zusammengefassten Variable festzulegen. Mit by() können wir Gruppen angeben, für die jeweils separate Werte berechnet werden:
cd D:\oCloud\Home-Cloud\Lehre\Methodenseminar\ // wo liegt der Datensatz?
use "Allbus_1980-2018.dta",clear
keep if year == 2014 & inc>0
collapse (mean) mean_inc=inc (median) median_inc=inc, by(educ sex)
browse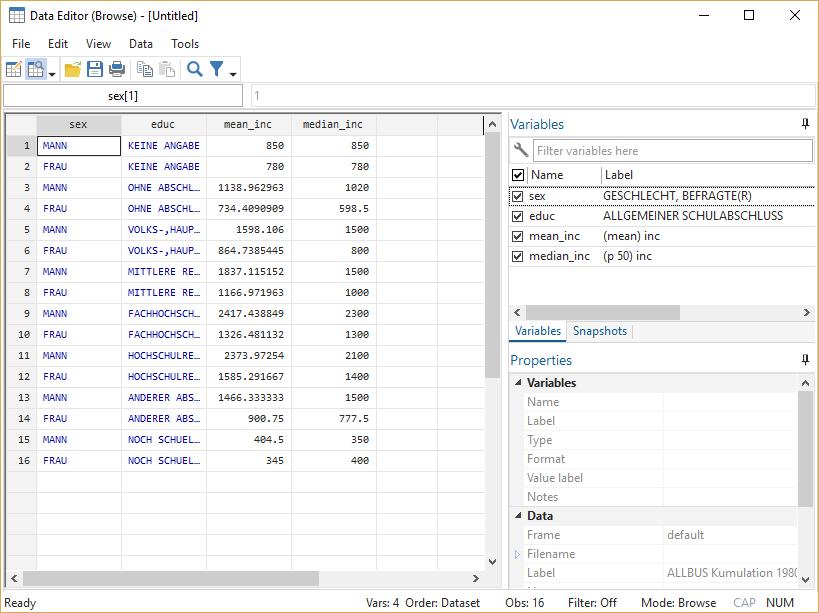
Anstelle von mean können alle Funktionen, die wir auch bei tabstat gesehen haben, verwenden siehe Kapitel 3.
11.8 Indikatoren umdrehen
Manchmal haben wir eine einzelne Likert-Skala, die wir “umdrehen” möchten. Bspw. stehen hohe Werte der Variable mm01 für eine hohe Zustimmung zur Aussage, dass die Ausübung des Islams in Deutschland beschränkt werden sollte. In mm02 stehen hohe Werte hingegen für eine hohe Zustimmung zur Aussage, dass der Islam zu Deutschland gehört:
use "Allbus_1980-2018.dta",clear
keep if year == 2016
mvdecode mm01 mm02, mv(-10 -9 -1)
d mm01 mm02
tab mm01
tab mm01,nol storage display value
variable name type format label variable label
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
mm01 byte %12.0g mm01 ISLAMAUSUEBUNG IN BRD BESCHRAENKEN
mm02 byte %12.0g mm02 ISLAM PASST IN DIE DEUTSCHE GESELLSCHAFT
ISLAMAUSUEBUNG IN |
BRD BESCHRAENKEN | Freq. Percent Cum.
--------------------+-----------------------------------
STIMME GAR NICHT ZU | 799 23.82 23.82
.. | 351 10.46 34.28
.. | 233 6.94 41.22
.. | 492 14.66 55.89
.. | 419 12.49 68.38
.. | 341 10.16 78.54
STIMME VOELLIG ZU | 720 21.46 100.00
--------------------+-----------------------------------
Total | 3,355 100.00
ISLAMAUSUEB |
UNG IN BRD |
BESCHRAENKE |
N | Freq. Percent Cum.
------------+-----------------------------------
1 | 799 23.82 23.82
2 | 351 10.46 34.28
3 | 233 6.94 41.22
4 | 492 14.66 55.89
5 | 419 12.49 68.38
6 | 341 10.16 78.54
7 | 720 21.46 100.00
------------+-----------------------------------
Total | 3,355 100.00Um aus beiden Variablen einen Index zu bilden, muss eine Variable umgedreht werden, sodass die Skalen beide inhaltlich in die gleiche Richtung laufen. Da mm01 von 1-7 reicht, können wir durch 1 - mm01 die Skala umkehren. Zur Kontrolle vergleichen wir die alte und die neue Variable abschließend:
(131 missing values generated)
| ISLAMAUSUEBUNG IN BRD BESCHRAENKEN
mm01a | STIMME GA .. .. .. .. .. STIMME VO | Total
-----------+-----------------------------------------------------------------------------+----------
1 | 0 0 0 0 0 0 720 | 720
2 | 0 0 0 0 0 341 0 | 341
3 | 0 0 0 0 419 0 0 | 419
4 | 0 0 0 492 0 0 0 | 492
5 | 0 0 233 0 0 0 0 | 233
6 | 0 351 0 0 0 0 0 | 351
7 | 799 0 0 0 0 0 0 | 799
-----------+-----------------------------------------------------------------------------+----------
Total | 799 351 233 492 419 341 720 | 3,355 Nachdem wir mm05 ebenfalls zu mm05a umgedreht haben, können wir einen Mittelwert aus den Indikatoren mm01-mm05 bilden:
11.9 recode
Mit der recode Funktion können Variablen umcodiert werden. Hier werden die Werte der Variable x2 zusammengefasst: 1 und 2 zu 1, aus 3 wird 2 und aus 4 bis 7 wird 3 - diese neue Codierung wird in der Variable nx2 abgelegt:
11.10 Informationen aus mehreren Datensätzen
Mit merge können wir Informationen aus mehreren Datensätzen zusammenfügen.
11.11 Arbeiten mit Textvariablen
Dafür helfen uns sog. “regular expressions”, in Stata stehen hierfür zb substr regexr und regexm zur Verfügung.
11.12 Link Liste
- Internet Guide to Stata
- Hilfeseiten der UCLA
- StataList-Forum
- Germán Rodríguezs Seiten enthalten viele Beispiele, Tricks und Erklärungen
Diese Beispiel bezieht sich also nur auf heterosexuelle Paare.↩︎