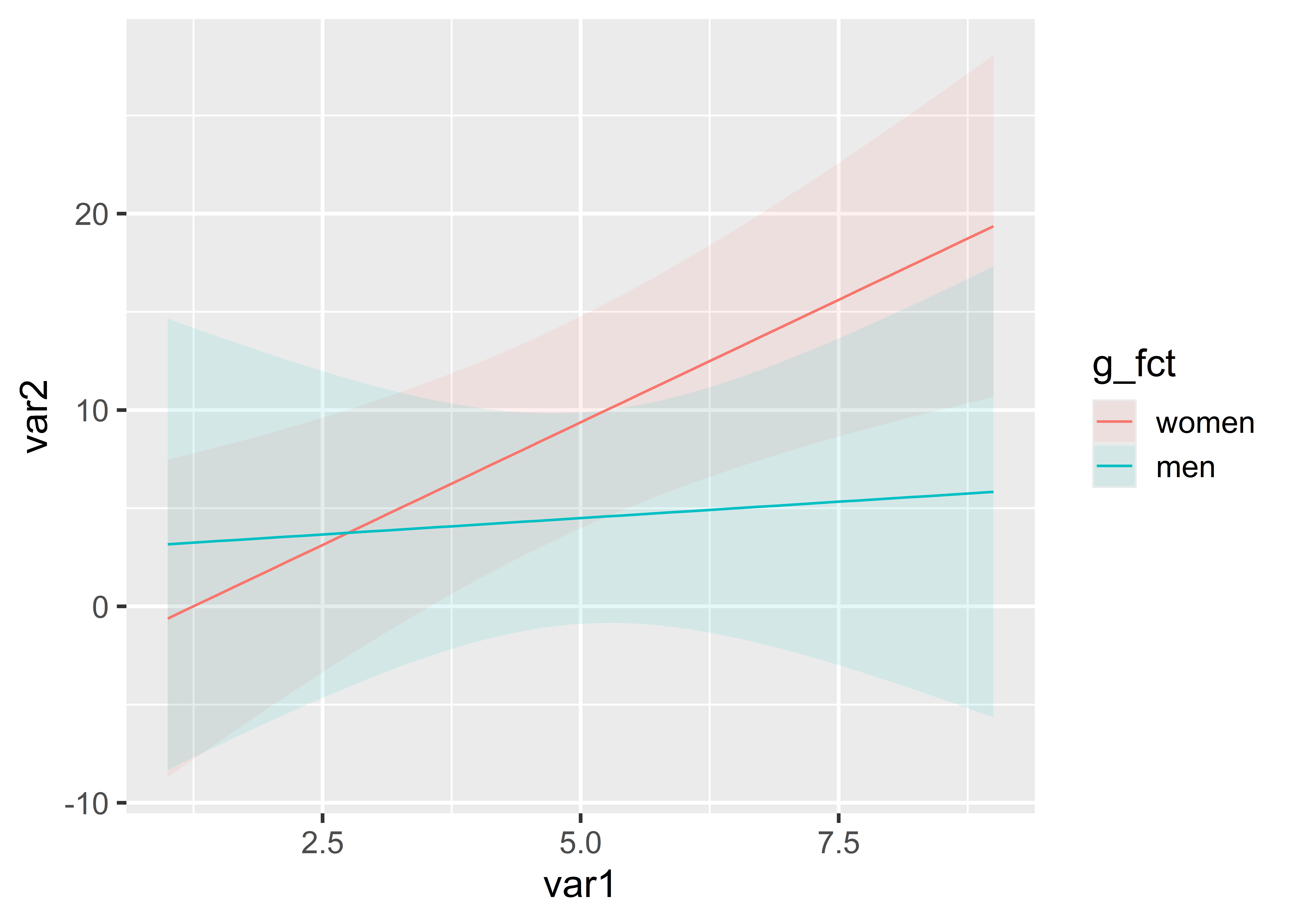
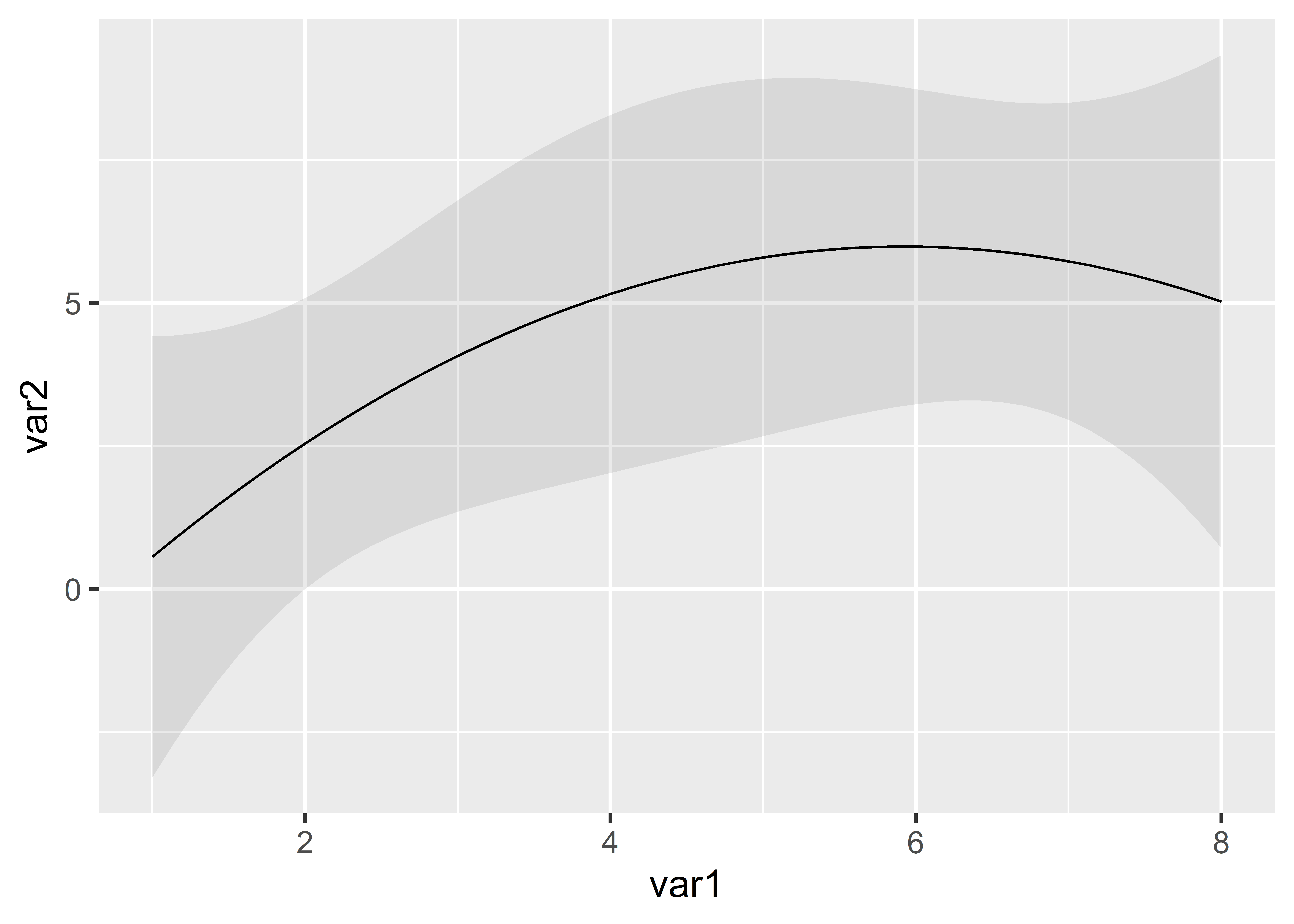
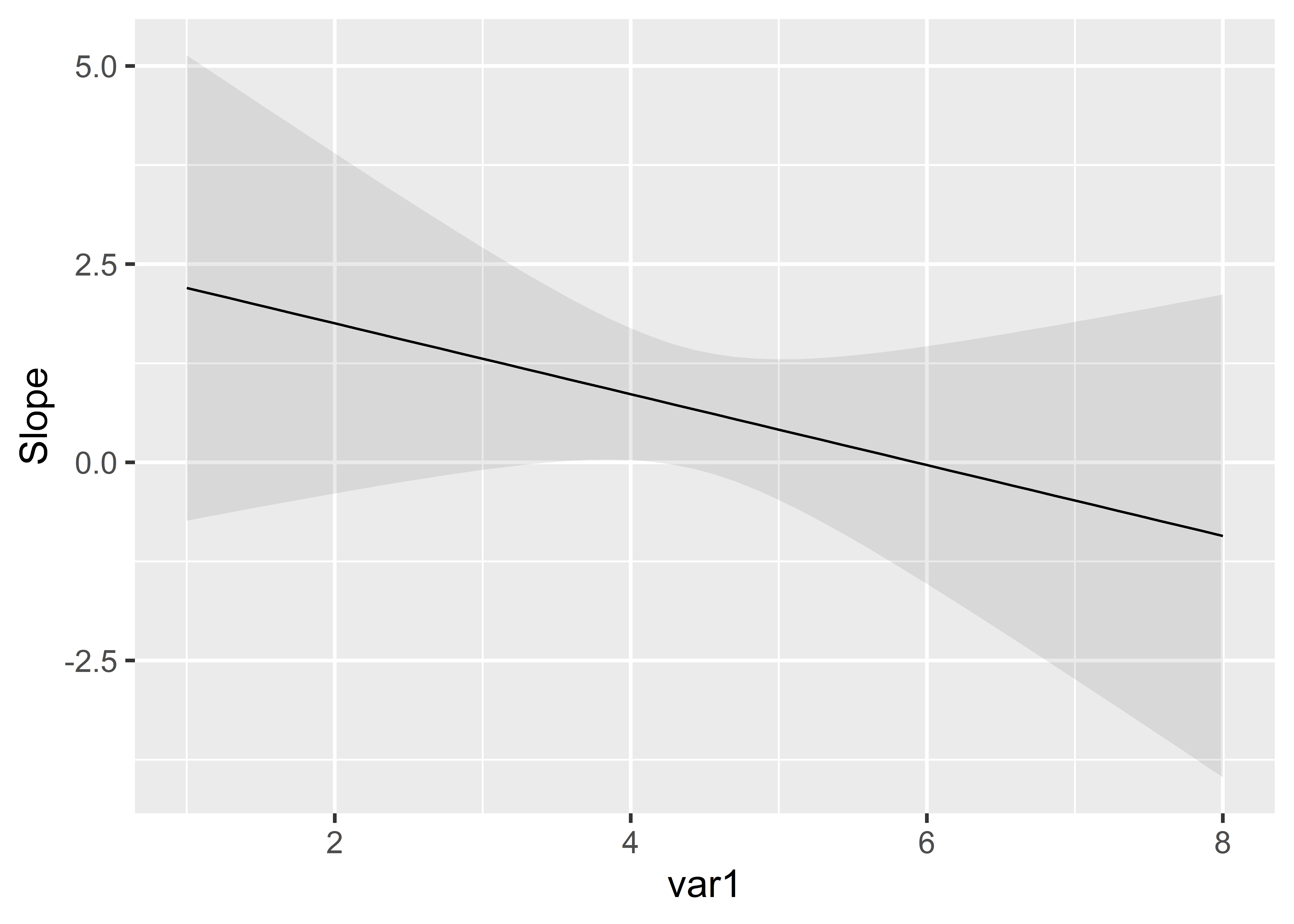
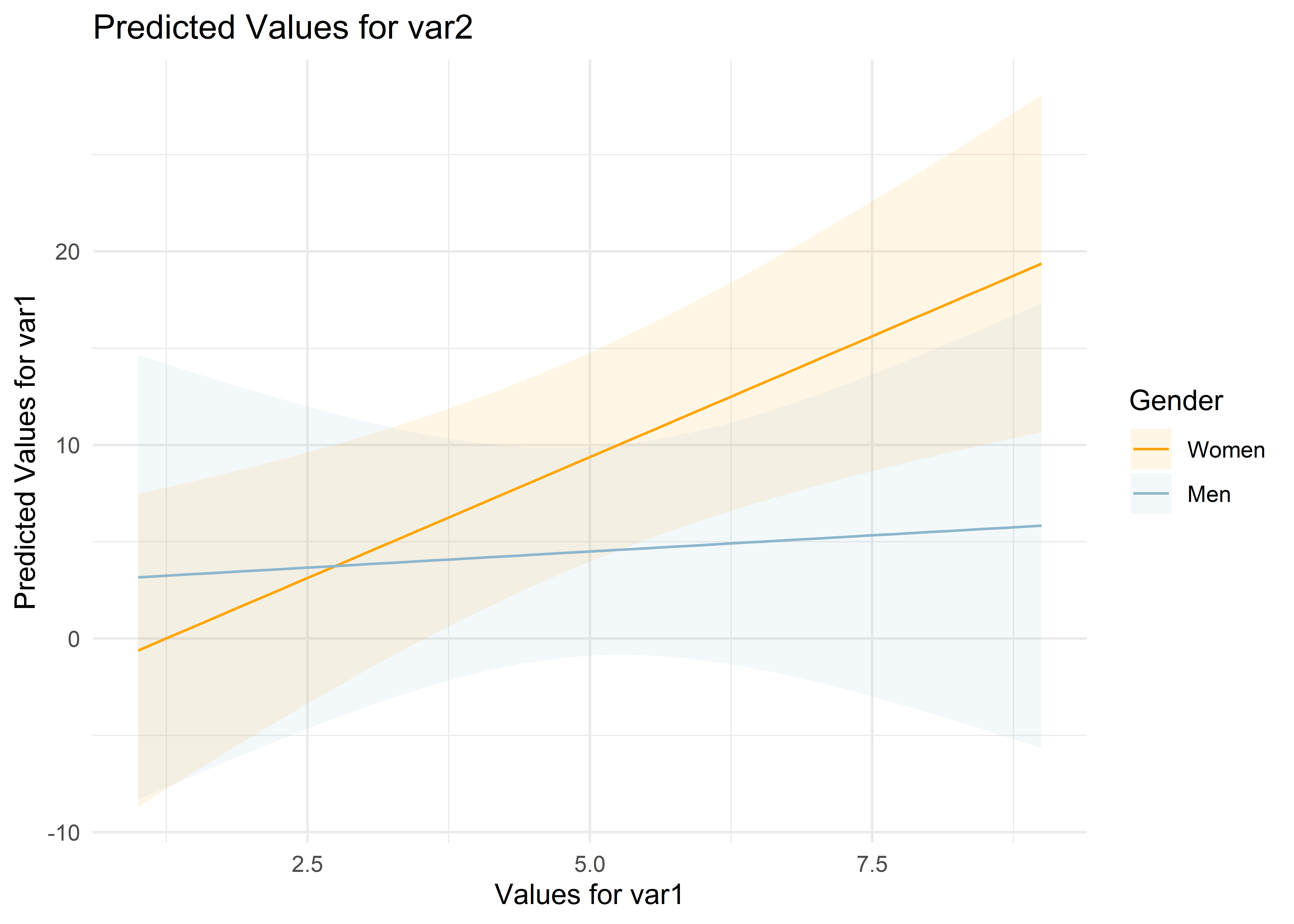When we compare models m1 and m3, we see different sample sizes:
m1 <-lm(var2 ~ var1, data = dat1) m4 <-lm(var2 ~ ed_fct + var1, data = dat1)modelsummary(list("m1"=m1,"m4"=m4), gof_omit ="IC|RM|Log|F")
tinytable_wlxerlegku5cm0jvsolp
m1
m4
(Intercept)
-2.340
-2.511
(4.345)
(5.681)
var1
1.839
1.753
(0.773)
(0.835)
ed_fctmedium
4.830
(6.038)
ed_fcthigh
-3.253
(6.554)
Num.Obs.
8
7
R2
0.486
0.700
R2 Adj.
0.400
0.400
It appears that in model m4, one case is lost with ed_fct. Why is that? It’s worth taking a look at the data:
dat1
id var1 var2 educ gend x ed_fct
1 1 2 2 3 2 2 high
2 2 1 2 1 1 1 basic
3 3 2 1 2 1 2 medium
4 4 5 9 2 2 4 medium
5 5 7 7 1 1 1 basic
6 6 8 4 3 2 NA high
7 7 9 25 2 1 NA medium
8 8 5 3 -1 2 NA <NA>
The value for ed_fct is missing for id = 8.
To compare the models, we should use only the rows where ed_fct values are available. We can manually select these rows (excluding id=8), but this can be cumbersome with larger datasets.
7.1.1complete.cases()
Here, complete.cases() is helpful. This function creates a logical variable that is TRUE for all complete cases (i.e., without NA). Incomplete cases are marked as FALSE. We specify which variables to consider for this check and add the variable to the dataset as a new column. For model 1, a case is considered complete if both var2 and var1 are present. So, we select the relevant variables with select() and apply complete.cases to this selection:
id var1 var2 educ gend x ed_fct compl_m1 compl_m4
1 1 2 2 3 2 2 high TRUE TRUE
2 2 1 2 1 1 1 basic TRUE TRUE
3 3 2 1 2 1 2 medium TRUE TRUE
4 4 5 9 2 2 4 medium TRUE TRUE
5 5 7 7 1 1 1 basic TRUE TRUE
6 6 8 4 3 2 NA high TRUE TRUE
7 7 9 25 2 1 NA medium TRUE TRUE
8 8 5 3 -1 2 NA <NA> TRUE FALSE
7.1.2 Finding Cases with Missing Values
Now, we can filter by these variables and examine these cases more closely. We filter for cases that are included in m1 (i.e., compl_m1 = TRUE) but not in m4 (compl_m4 = FALSE):
dat1 %>%filter(compl_m1 == T & compl_m4 == F)
id var1 var2 educ gend x ed_fct compl_m1 compl_m4
1 8 5 3 -1 2 NA <NA> TRUE FALSE
7.1.3 Calculating Models with Only Complete Cases
We can now create model m1 to include only cases that are also considered in model m4:
m1_m4vars <-lm(var2 ~ var1, data =filter(dat1, compl_m4 == T))modelsummary(list("m1"=m1,"m1 with m4vars"=m1_m4vars,"m4"=m4), gof_omit ="IC|RM|Log|F")
tinytable_rc35evn7tax8cahz4sg8
m1
m1 with m4vars
m4
(Intercept)
-2.340
-1.832
-2.511
(4.345)
(4.646)
(5.681)
var1
1.839
1.848
1.753
(0.773)
(0.814)
(0.835)
ed_fctmedium
4.830
(6.038)
ed_fcthigh
-3.253
(6.554)
Num.Obs.
8
7
7
R2
0.486
0.508
0.700
R2 Adj.
0.400
0.409
0.400
Now, both m1 with m4vars and m4 have the same number of cases, allowing for a direct comparison of the results.
7.2 Interactions
Interactions between two variables can be calculated using *:
For binary dependent variables, logistic regression models are a widely used tool. We can fit logistic regression models in R using glm() - for an example, we turn to PSM0100 (Usage of social networks yes = 1, no = 2) :
m2 <-glm(soc_med ~ palter, family ="binomial", data = pend10)summary(m2)
Call:
glm(formula = soc_med ~ palter, family = "binomial", data = pend10)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.194321 0.107660 29.67 <2e-16 ***
palter -0.073518 0.002315 -31.75 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 7557.2 on 5461 degrees of freedom
Residual deviance: 6217.5 on 5460 degrees of freedom
AIC: 6221.5
Number of Fisher Scoring iterations: 3
The interpretation of the \(\beta\) coefficients from a logistic regression model pertains to the logits (the logarithms of the odds): There is a statistically significant relationship at the 0.001 level between age and the probability of using social media. With each additional year of age, there is a decrease of 0.073518 in the logits* of the respondents using social media.*
7.4.1 average marginal effects
Logits are quite cumbersome—so how does the probability of \(\texttt{soc\_med} = 1\) change with palter? Here, we face the challenge that the derivative of the “inverse function” is not as straightforward as in the case of OLS. If we modify the regression equation from above1 with exp() and \(p=\frac{Odds}{1+Odds}\), we get:
We would need to differentiate this expression with respect to palter to determine how the predicted probability of \(\texttt{soc\_med} = 1\) changes with each additional year of respondent age. Given that palter appears in both the exponent of the e function and both the numerator and denominator (“top and bottom”), the differentiation becomes significantly more complex than in the previous lm() models.
For our purposes, it is crucial to note that to compute changes in the predicted probabilities, we need the so-called marginal effects from the {marginaleffects} package. This package includes the avg_slopes() function, which allows us to calculate a \(\beta\) representing the change in the probability of \(\texttt{soc\_med} = 1\) in relation to palter. This is known as the average marginal effect, as it provides the average marginal change in the dependent variable for a one-unit increase in the independent variable.
fdz_install("marginaleffects") # nur einmal nötiglibrary(marginaleffects)
With each additional year of age, there is on average a decrease of 0.01419 (1.419 percentage points) in the probability of using social media.
7.5 Weighted Regression Model
The {survey} package allows including weights when fitting regression model:
fdz_install("survey")
library(survey)pend <- haven::read_dta("./orig/PENDDAT_cf_W13.dta") %>%filter(netges >0 , palter >0, azges1 >0) %>%mutate(zpsex_fct =factor(zpsex, levels =1:2, labels =c("M","W")))wgt_df <- haven::read_dta("./orig/pweights_cf_W13.dta")pend_wgt <- pend %>%left_join(wgt_df, by =join_by(pnr,welle))modx <-lm(netges ~ palter +I(palter^2),data=pend) # conventional lm() model# create new data.frame including weights using svydesign() from survey-packagepend_weighted <-svydesign(id =~pnr, # id variableweights =~wqp, # weight variabledata = pend_wgt) # original unweighted data # family = gaussian() provides a linear regression model, like lm() - but respecting weightssurvey_modx <-svyglm(netges ~ palter +I(palter^2), family =gaussian(), data = etb18,design = pend_weighted)modelsummary(list("lm()"=modx,"svyglm()"= survey_modx),gof_omit ="RM|IC|Log")
tinytable_fu7vjx5bc5ehko34nu0r
lm()
svyglm()
(Intercept)
811.753
463.721
(354.363)
(504.015)
palter
24.640
53.580
(17.071)
(26.471)
I(palter^2)
-0.147
-0.489
(0.197)
(0.314)
Num.Obs.
7996
7996
R2
0.004
0.007
R2 Adj.
0.004
-2.252
F
15.525
8.495
7.6 “Robust” Standard Errors
Often, standard errors need to be adjusted for violations of general assumptions (homoscedasticity, etc.).
The good news is that R offers several ways to correct standard errors, including with {sandwich} or {estimatr}.
A very simple option is the correction of standard errors in {modelsummary}, which we will look at in more detail:
We can request heteroskedasticity-consistent (HC) “robust” standard errors with the vcov option HC in modelsummary(). The help page for {modelsummary} provides a list of all options.
One option is also stata, to replicate results from Stata’s , robust. More here about the background and differences.
We can estimate the following model:
mod1 <-lm(netges ~ palter +I(palter^2),data=pend)
In the modelsummary(), we can now display the same model with different adjustments for the standard errors:
{fixest}) offers a wide range of options: logistic FE models, multi-dimensional fixed effects, multiway clustering, etc. And it is very fast, e.g., faster than Stata’s reghdfe. For more details, the vignette is recommended.
The central function for estimating linear FE regression models is feols() - it works very similarly to lm(). We provide a formula following the pattern dependent variable ~ independent variable(s). We simply add the variable that specifies the FEs with |:
library(fixest)fe_mod1 <-feols(netges ~ palter +I(palter^2) | pnr, data = pend)fe_mod1
{fixest} automatically clusters the standard errors along the FE variable (here pnr). If we don’t want that, we can request unclustered SEs with the se option = "standard":
With lmer(), we can estimate a random intercept model by specifying ( 1 | pnr), which indicates that a separate random intercept should be calculated for each pnr: