In diesem Kapitel widmen wir uns dem Fall einer binären abhängigen Variable/Dummyvariable. Für solche Fälle sind logistische Regressionsmodelle gebräuchlich, die sich in Ihrer Anwendung etwas von ‘normalen’, linearen Regressionsmodellen unterscheiden. Kern dieses Unterschieds ist die Link-Funktion, welche die Koeffizienten etwas schwerer interpretierbar macht - daher haben sich sog. marginal effects als Darstellungsform für Ergebnisse logistischer Regressionen etabliert. In R steht uns dafür das Paket {marginaleffects}, welches sich in der Anwendung sehr dem margins-Befehl in Stata ähnelt.
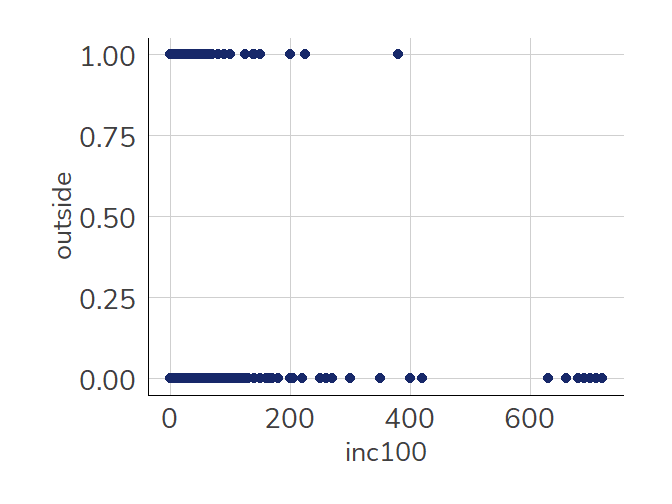
Bisher hatten wir immer Regressionsmodelle betrachtet, die eine metrisch skalierte abhängige Variable hatten.1 Aber gerade Individualmerkmale sind nur selten metrisch skaliert, z.B. Erwerbstatus, Familienstand, Geschlecht, Elternstand, … Ein lineares OLS-Regressionsmodell wie wir es bisher kennen gelernt haben, hilft uns hier nicht weiter. Schauen wir uns beispielsweise die Arbeitsplatzsituation der männlichen Befragten in der ETB 2018 an (F605)2 :
Arbeiten Sie mehr als die Hälfte Ihrer Arbeitszeit im Freien?
Die 1 steht dabei jeweils für “ja”, die 2 für “nein”. Wir verändern die Codierung aber so, dass die “nein”-Antworten mit 0 versehen werden. Die neue Variable nennen wir outside. Außerdem teilen wir F518_SUF durch 100 und legen die so erstellte Variable “Einkommen in 100EUR” in inc100 ab, um die Nachkommastellen des Koeffizienten zu reduzieren:
In R können wir ein solches Modell mit glm() und der Option family="binomial" berechnen:3
m2 <-glm(outside ~ inc100, family ="binomial", data = m_etb18)summary(m2)
Call:
glm(formula = outside ~ inc100, family = "binomial", data = m_etb18)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.9580 -0.6005 -0.4841 -0.3042 5.5160
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.54045 0.07285 -7.419 1.18e-13 ***
inc100 -0.03861 0.00218 -17.716 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 6643.5 on 8431 degrees of freedom
Residual deviance: 6209.8 on 8430 degrees of freedom
AIC: 6213.8
Number of Fisher Scoring iterations: 6
Die Interpretation der \(\beta\) aus einem logistischen Regressionsmodell bezieht sich also auf die Logits (die logarithmierten Odds):
Es besteht ein am 0,001-Niveau signifikanter Zusammenhang zwischen dem Einkommen und der Wahrscheinlichkeit, im Freien zu arbeiten. Mit einem um 100 Euro höheren Einkommen gehen um 0.038612 niedrigere Logits einher, mehr als die Hälfte Ihrer Arbeitszeit im Freien zu arbeiten.
10.2 average marginal effects
Logits sind aber sehr unhandlich - wie verändert sich jetzt aber die Wahrscheinlichkeit für \(\texttt{outside} = 1\) mit inc100? Hier haben wir das Problem, dass die Ableitung der “rücktransformierten Funktion” nicht so einfach ist wie im Fall der OLS. Verändern wir nämlich auch die Regressionsgleichung von oben4 mit exp() und \(p=\frac{Odds}{1+Odds}\), so landen wir bei
Diesen Ausdruck müssten wir nach inc100 ableiten, um eine Antwort zu bekommen um wieviel sich die vorhergesagte Wahrscheinlichkeit für \(\texttt{outside} = 1\) mit einem um einen Euro höheren Befragteneinkommen verändert. Durch die Tatsache dass inc hier im Exponenten der e-Funktion und sowohl im Dividenden als auch Divisor (“oben und unten”) steht, wird die Ableitung hier aber deutlich komplizierter als das in den bisherigen lm()-Modellen der Fall war. Für uns ist an dieser Stelle aber nur wichtig, dass wir für die Berechnung der Veränderung der vorhergesagten Wahrscheinlichkeiten die sog. marginalen Effekte aus dem Paket {marginaleffects} brauchen. Darin findet sich der Befehl avg_slopes(), welcher uns erlaubt ein \(\beta\) zwischen dem Einkommen und der Wahrscheinlichkeit für \(\texttt{outside} = 1\) zu berechnen. Dieses wird auch als average marginal effect bezeichnet, da sie den durchschnittlichen marginalen Effekt der betrachteten unabhängigen Variable auf die abhängige Variable wiedergeben.
install.packages("marginaleffects") # nur einmal nötiglibrary(marginaleffects)
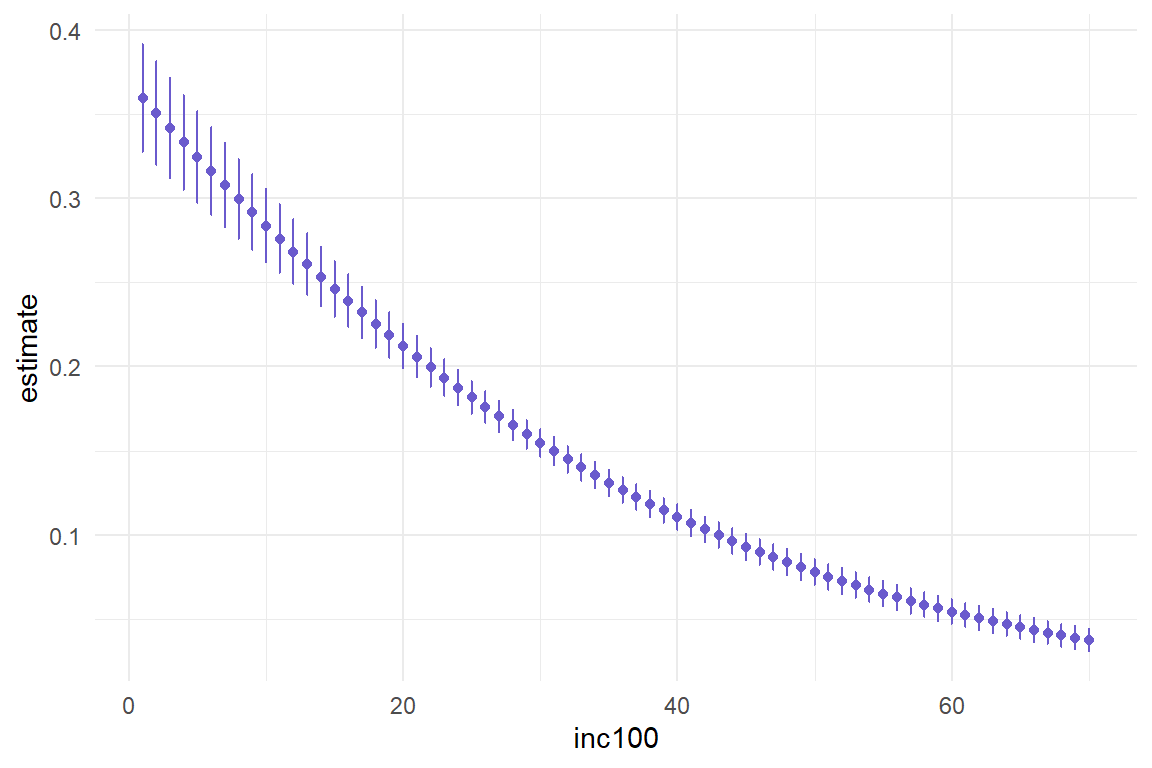
Mit einem um 100 Euro (inc100 ist in 100 EUR gemessen) höheren Einkommen geht im Durchschnitt eine um 0.00426 (0.42632 Prozentpunkte) geringere Wahrscheinlichkeit einher, mehr als die Hälfte der Arbeitszeit im Freien zu arbeiten.
10.3 Predctions
Alternativ können die Ergebnisse aus log. Regressionen auch als vorhergesagte Werte dargestellt werden. Vorhergesagte Werte können wir mit predictions() aus {marginaleffects} erstellen:
Erstellen Sie ein logistisches Regressionsmodell mit fam_beruf basierend auf der Frage
Haben Sie aufgrund ihrer Kinder Abstriche gemacht, um Familie und Beruf zu vereinbaren?
als abhängiger Variable (1 = ja, 0 = nein.) Verwenden Sie die Ausbildung m1202 als unabhängige Variable.
Berechnen Sie die AME mit marginaleffects.
10.7 Anhang: Hintergrund zu log. Regression & average marginal effects
Wenn wir uns fragen, ob sich Befragte mit höherem Einkommen seltener im Freien arbeiten, hilft uns die OLS-Vorgehensweise nicht so richtig weiter. Die “Punktewolke” zur Optimierung der Abweichung zwischen tatsächlichen und vorhergesagten Werten (Residuen) sieht hier anders aus als bisher:
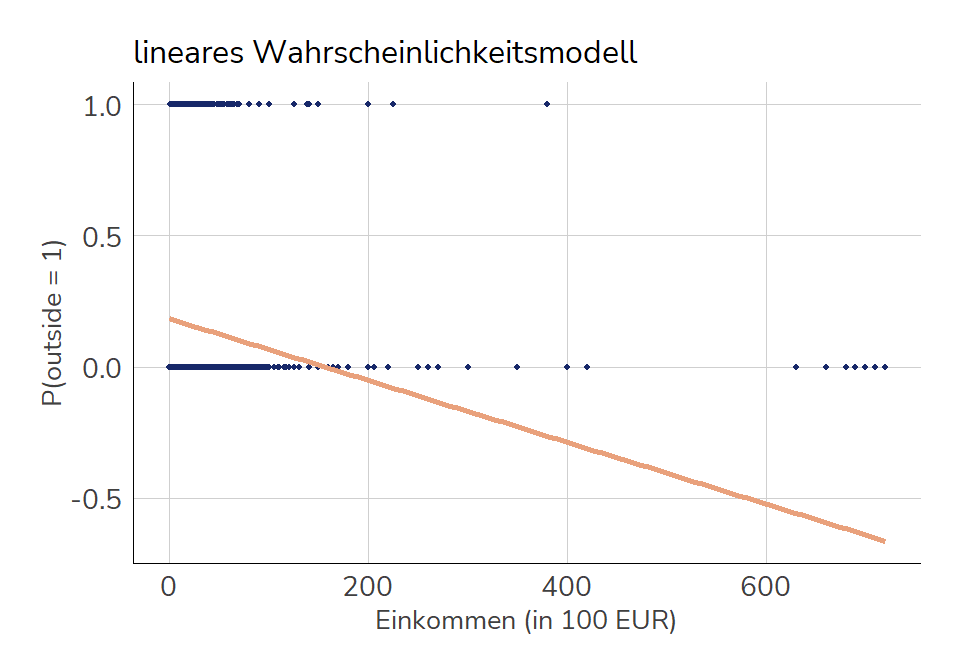
Um trotzdem ein Regressionsmodell zu berechnen, könnten wir die abhängige Variable uminterpretieren. \(\hat{y}\) wird dann nicht mehr dichotom, sondern als metrische Wahrscheinlichkeit interpretiert, dass der Befragte mehr als die Hälfte der Arbeitszeit im Freien arbeitet (also die Wahrscheinlichkeit für outside = 1). Das können wir dann wie gehabt in eine Regressionsgleichung aufnehmen, zB. mit dem Einkommen als unabhängiger Variable:
Allerdings führt das zwangsläufig zu Verstößen gegen die Annahmen bzgl. der Residuen - die Fehler werden immer heteroskedastisch und nicht normalverteilt sein. Zudem wird es vorhergesagte Werte geben, die nicht sinnvoll interpretiert werden können, weil es mit 0 und 1 Grenzen gibt, jenseits derer Wahrscheinlichkeiten nicht existieren (zB gibt es keine negativen Wahrscheinlichkeiten).
Code
ggplot(m_etb18, aes(x = inc100, y = outside)) +geom_point(color ="#172869", size = .75) +geom_smooth(method ="lm", color =lacroix_palette("PeachPear",6)[2],se = F ) +labs(y ="P(outside = 1)", x ="Einkommen (in 100 EUR)",title ="lineares Wahrscheinlichkeitsmodell")
Um diese Probleme zu umgehen, sind für dichotome abhängige Variablen logistische Regressionsmodelle ein sehr verbreitetes Vorgehen. Dafür werden neben dem bereits angesprochenen Schritt der Betrachtung von \(\hat{y}\) als Wahrscheinlichkeit zwei weitere Transformationen der abhängigen Variable vorgenommen:
Odds statt Wahrscheinlichkeiten: Um die obere Grenze des Wertebereichs der abhängigen Variablen auf \(+\infty\) auszudehnen, werden statt Wahrscheinlichkeiten Odds betrachtet. Odds sind definiert als der Quotient aus Wahrscheinlichkeit und der Gegenwahrscheinlichkeit für ein gegebenes Ereignis. In unserem Beispiel sind also die Odds dafür, dass eine Befragter angibt, sich nachts outside zu fühlen: \[Odds(outside=1) = \frac{P(outside=1)}{P(outside=0)}= \frac{P(outside=1)}{1-P(outside=1)} \] Die Odds gehen gegen 0, je unwahrscheinlicher das betrachtete Ereignis ist. Für sehr wahrscheinliche Ereignisse nehmen die Odds Werte an, die gegen \(+\infty\) gehen, das Verhältnis zwischen Dividend (“Zähler”) und Divisor (“Nenner”) wird immer größer.
Logits statt Odds: Damit bleibt aber noch das Problem der negativen Werte bestehen: Auch Odds sind nur für [0;\(+\infty\)] definiert. Um auch den negativen Wertebereich sinnvoll interpretierbar zu machen, werden die Odds logarithmiert, wir erhalten die sogenannten Logits: \[Logit(outside=1) = log(Odds(outside=1)) = log\left(\frac{P(outside=1)}{1-P(outside=1)}\right)\] Die Logarithmierung führt für Werte zwischen 0 und 1 zu negativen Werten, für Werte größer als 1 zu positiven Werten.
Dementsprechend gibt es bei logistischen Regressionen drei Einheiten:
Wahrscheinlichkeiten \(P = \frac{\text{Anzahl Treffer}}{\text{Anzahl aller Möglichkeiten}}\)
Zunächst stellt sich die Frage, was Logits denn bedeuten. Eigentlich möchten wir ja Wahrscheinlichkeiten im Wertebereich zwischen 0 und 1 (bzw. 0% und 100%) als Interpretationseinheit haben. Die Berechnung eines vorhergesagten Werts für einen Befragten mit einem Einkommen von 1000 Euro (inc100=10) ergibt durch einsetzen bzw. predict() natürlich auch die Logits:
summary(m2)$coefficients
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.54045018 0.072851290 -7.41854 1.184188e-13
inc100 -0.03861198 0.002179513 -17.71588 3.162624e-70
-0.53856546+-0.03868975*10
[1] -0.925463
predict(m2, data.frame(inc100 =10))
1
-0.9265699
Befragte mit einem Einkommen von 1000EUR haben dem Modell zu Folge Logits von -0.92657, mehr als die Hälfte der Arbeitszeit im Freien zu arbeiten.
Um an die Wahrscheinlichkeit für outside = 1 zu bekommen, müssen wir die Transformationsschritte sozusagen “rückabwickeln”! Dafür müssen wir zunächst mit exp den ln() vor den Odds heraus rechnen und können dann durch die die Formel \(p=\frac{Odds}{1+Odds}\) die Wahrscheinlichkeit aus den odds berechnen:
exp(logits)/(1+exp(logits)) # beide Schritte auf einmal
[1] 0.2838461
Die Wahrscheinlichkeit, dass ein Befragter mit einem Einkommen von 1000 Euro angibt, mehr als die Hälfte Ihrer Arbeitszeit im Freien zu arbeiten, liegt also unserem Modell zu Folge bei 28.362%.
Mit der Option type="response" können wir das auch mit predict() direkt berechnen:
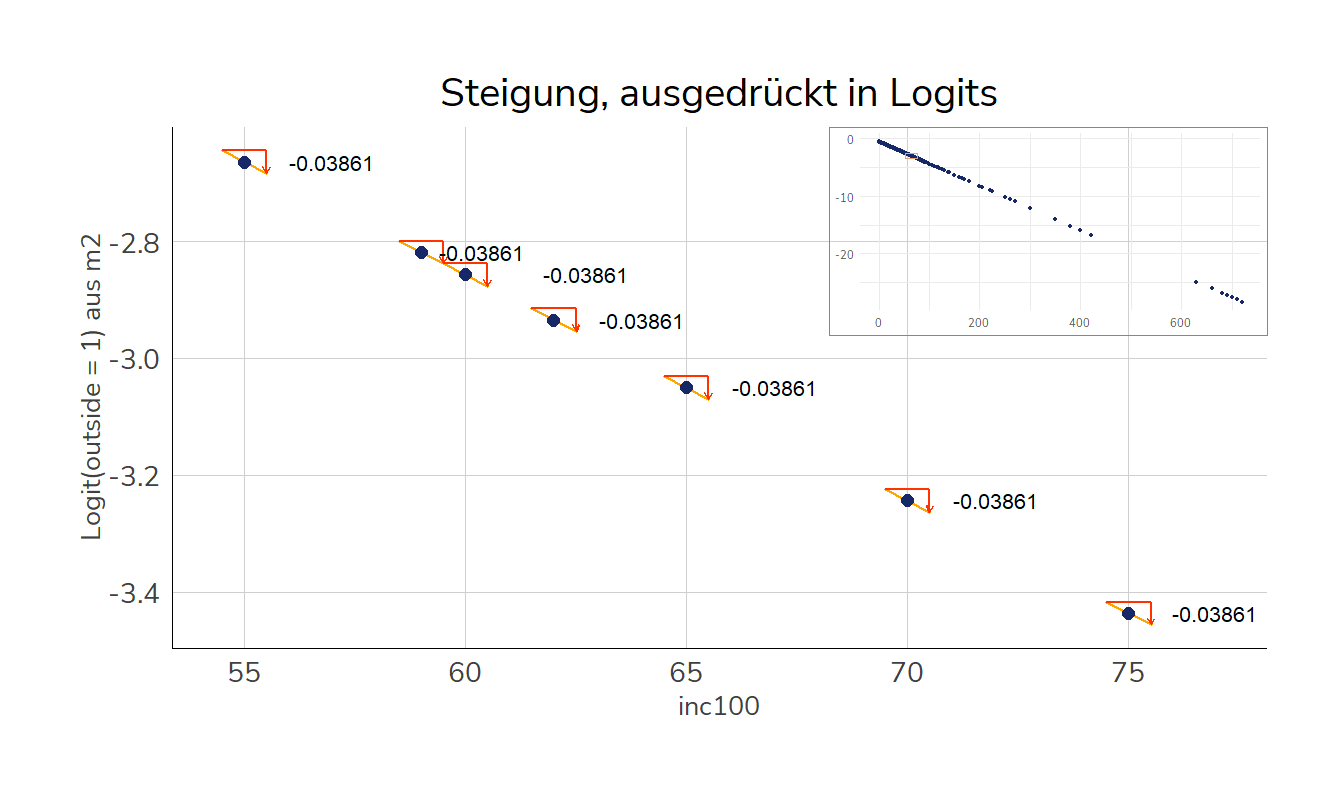
Wie verändern sich dann die vorhergesagten Werte, wenn wir inc100 um eine Einheit (also 100€) erhöhen? Die Logits verändern sich pro Einheit inc100 natürlich genau um \(\hat\beta1\), also hier -0.03861. Um sich die Steigung an einigen Werten anzusehen, berechnen wir jeweils die Abstände der vorhergesagten Werte für \(x-0.5\) und \(x+0.5\):
Um die Werte jeweils mit dem eingesetzten Wert zu beschriften, stellen wir den Wert mit ""=voran:
Die Differenzen sind immer gleich - entsprechend der Interpretation gehen mit einem um eine Einheit höheren inc100 um 0.03861 höhere Logits einher, dass die Befragten mehr als die Hälfte Ihrer Arbeitszeit im Freien arbeiten:
Steigung bei inc100 = 55: -2.68341 \(-\) -2.64480 = -0.03861
Steigung bei inc100 = 65: -3.06953 \(-\) -3.03092 = -0.03861
Steigung bei inc100 = 75: -3.45565 \(-\) -3.41704 = -0.03861
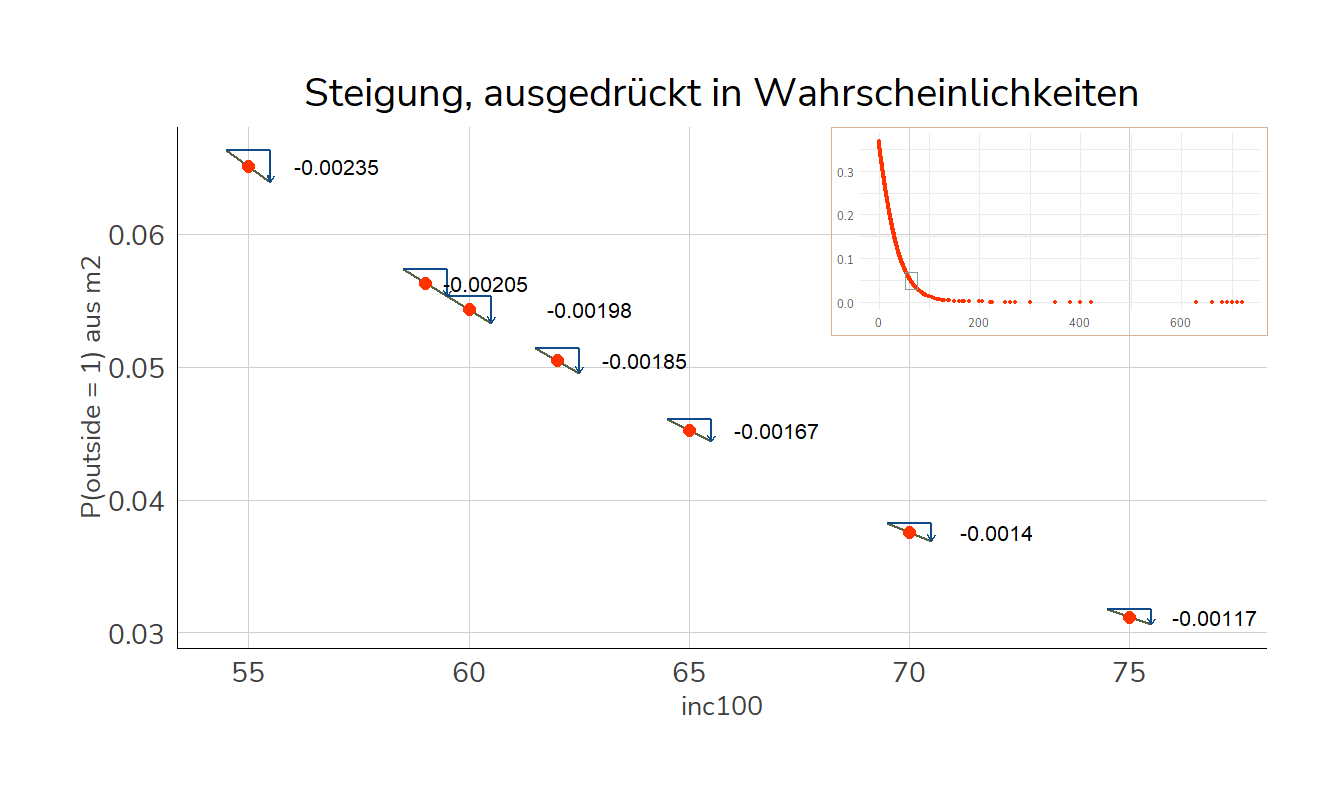
Wenn wir uns diese Schritte aber jeweils für die vorhergesagten Wahrscheinlichkeiten ansehen, sieht das aber anders aus:
predict(m2, data.frame(inc100=c("54.5"=54.5,"55.5"=55.5,"64.5"=64.5,"65.5"=65.5,"74.5"=74.5,"75.5"=75.5)), type ="response")
Hier werden die Differenzen mit zunehmendem inc100 immer kleiner:
Steigung bei inc100 = 55: 0.06396 \(-\) 0.06631 = -0.00235
Steigung bei inc100 = 65: 0.04438 \(-\) 0.04605 = -0.00167
Steigung bei inc100 = 75: 0.03060 \(-\) 0.03177 = -0.00117
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
Diese Steigungen werden für alle Beobachtungen aus dem zu Grunde liegenden Datensatz aufsummiert und dann der Durchschnitt gebildet (\(\rightarrow\)average marginal effects)
10.8 Links
Die Seite zu {marginaleffects} bietet sehr ausführliche und anschauliche Beispiele zu den verschiedenen Varianten marginaler Effekte
Die Einschränkung auf männliche Befragte hat hier den einfachen Grund, dass so der Koeffizient größer ist↩︎
family="binomial" ist dabei entscheidend: glm(outside ~ inc100, data = m_etb18) oder glm(outside ~ inc100, family = gaussian(), data = m_etb18) ist gleichbedeutend mit lm(outside ~ inc100, data = m_etb18): es wird ein lineares OLS-Modell berechnet.↩︎