funktion(objektname1,
option1 = sehr_lange_Auswahl_die_sehr_lang_ist,
option2 = noch_eine_Auswahl_Option2)2 Arbeiten mit Datensätzen in R
(Spätes) Vorwort zu R und der Befehlsstruktur
- Alles ist ein Objekt.
- Alles hat einen Namen.
- Alles was wir tun basiert auf Funktionen.
- Funktionen kommen aus “packages”1, aber wir werden auch eigene Funktionen schreiben.
Punkt 1. und 2. wird als Objektorientierte Programmierung (object-orientated programming, OOP) bezeichnet. Wir werden in diesem Kurs also objektorientierte Programmierung lernen.
Klingt gut, oder?
- Funktionen sind (fast) immer Verben gefolgt von einer Klammer, bspw.
colnames(), in welcher das zu bearbeitende Objekt angegeben wird. Das kann bspw. eine Variable oder ein Datensatz sein - Außerdem werden in den Klammern auch ggf. Optionen angegeben - bspw. sehen wir unten den Einlesebefehl für .csv-Dateien:
read.csv(datei.csv, header = T, sep = ",") - Zeilenumbrüche werden von R ignoriert, d.h. wir können einen Befehl über mehre Zeilen schreiben - bspw. um es etwas übersichtlicher zu halten:
- Wenn wir eine Funktion durchführen mit
funktion(objektname, option1 = TRUE, option2 = FALSE)bekommen wir das Ergebnis in der Konsole ausgegeben. - Soll das Ergebnis einer Berechnung oder Operation nicht nur angezeigt werden, sondern für weitere Schritte behalten werden, muss mit
name <- ...das Ergebnis unternameabgelegt werden. Das Ausgangsobjekt bleibt unverändert - außer wir überschreiben das Ausgangsobjekt explizitname <- funktion(name). Hier im Skript werde ich sehr häufig den Schritt des Ablegens weglassen, weil wir ja direkt sehen wollen, was passiert. Wenn wir aber mit bisherigen Operationen weiterarbeiten wollen, dann müssen wir sie in R unter einem Objektnamen ablegen. - Optionen innerhalb einer
()können auch einfach auf Basis der Reihenfolge angegeben werden - Mit
?funktion()ist die Hilfe aufrufbar, bspw.?colnames()
Ein paar allgemeine Aspekte, in denen sich das Arbeiten mit R von dem mit einigen anderen Programmen unterscheidet:
R stoppt nicht notwendigerweise bei einem Syntaxfehler, sondern versucht den Rest der Befehle auszuführen. Aber: RStudio stoppt ab Version 2022.07 bei einem Syntaxfehler.
Für alle Stata-Nutzenden: kein
variable xyz already definedmehr. Wir können alles überschreiben, ohne, replaceoder ähnliches.Durch die Objektorientierung haben wir die Möglichkeit mehrere Datensätze gleichzeitig geöffnet zu haben - das erhöht die Flexibilität.
In der ersten Session haben wir einige Schritte mit der Taschenrechnerfunktion in R unternommen. Die wirkliche Stärke von R ist aber die Verarbeitung von Daten - los geht’s.
2.1 Datenstrukturen in R: data.frame
Im vorherigen Kapitel haben wir die Studierendenzahlen der Uni Bremen (19173), Uni Vechta (5333) und Uni Oldenburg (15643) zusammen unter studs abgelegt und mit den in profs abgelegten Professurenzahlen ins Verhältnis gesetzt. Das funktioniert soweit gut, allerdings ist es übersichtlicher, zusammengehörige Werte auch zusammen ablegen. Dafür gibt es in R data.frame. Wir können dazu die beiden Objekte in einem Datensatz ablegen, indem wir sie in data.frame eintragen und das neue Objekt unter dat1 ablegen. Wenn wir dat1 aufrufen sehen wir, dass die Werte zeilenweise zusammengefügt wurden:
studs <- c(19173,5333,15643) # Studierendenzahlen unter "studs" ablegen
profs <- c(322,67,210) # Prof-Zahlen unter "profs" ablegen
dat1_orig <- data.frame(studs, profs)
dat1_orig studs profs
1 19173 322
2 5333 67
3 15643 210dat1 <- data.frame(studs = c(19173,5333,15643),
profs = c(322,67,210),
gegr = c(1971,1830,1973)) # ohne zwischen-Objekte
dat1 # zeigt den kompletten Datensatz an studs profs gegr
1 19173 322 1971
2 5333 67 1830
3 15643 210 1973In der ersten Zeile stehen also die Werte der Uni Bremen, in der zweiten Zeile die Werte der Uni Vechta usw. Die Werte können wir dann mit datensatzname$variablenname aufrufen. So können wir die Spalte profs anzeigen lassen:
dat1$profs [1] 322 67 210Mit colnames()/names() können wir die Variablen-/Spaltennamen des Datensatzes anzeigen lassen, zudem können wir mit nrow und ncol die Zahl der Zeilen bzw. Spalten aufrufen:
colnames(dat1) ## Variablen-/Spaltennamen anzeigen[1] "studs" "profs" "gegr" names(dat1) ## Variablen-/Spaltennamen anzeigen[1] "studs" "profs" "gegr" ncol(dat1) ## Anzahl der Spalten/Variablen[1] 3nrow(dat1) ## Anzahl der Zeilen/Fälle[1] 3Neue zusätzliche Variablen können durch datensatzname$neuevariable in den Datensatz eingefügt werden:
dat1$stu_prof <- dat1$studs/dat1$profs
## dat1 hat also nun eine Spalte mehr:
ncol(dat1) [1] 4dat1 studs profs gegr stu_prof
1 19173 322 1971 59.54348
2 5333 67 1830 79.59701
3 15643 210 1973 74.49048Wir können auch ein oder mehrere Wörter in einer Variable ablegen, jedoch müssen Buchstaben/Wörter immer in "" gesetzt werden.
dat1$uni <- c("Uni Bremen","Uni Vechta", "Uni Oldenburg")
dat1 studs profs gegr stu_prof uni
1 19173 322 1971 59.54348 Uni Bremen
2 5333 67 1830 79.59701 Uni Vechta
3 15643 210 1973 74.49048 Uni OldenburgMit View(dat1) öffnet sich zudem ein neues Fenster, in dem wir den gesamten Datensatz ansehen können:
View(dat1)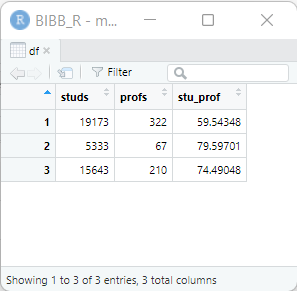
2.2 Variablentypen
Damit haben wir bisher zwei Variablentypen kennen gelernt: numeric (enthält Zahlen) und character (enthält Text oder Zahlen, die als Text verstanden werden sollen). Darüber hinaus gibt es noch weitere Typen, die besprechen wir wenn sie nötig sind, zB. gibt es factor-Variablen, die eine vorgegebene Sortierung und Werteuniversum umfassen oder logische Variablen. Vorerst fokussieren wir uns auf character und numeric Variablen. Mit class() kann die Art der Variable untersucht werden oder mit is.numeric() bzw. is.character() können wir abfragen ob eine Variable diesem Typ entspricht:
class(dat1$profs)[1] "numeric"class(dat1$uni)[1] "character"is.numeric(dat1$profs)[1] TRUEis.character(dat1$profs)[1] FALSEMit as.character() bzw. as.numeric() können wir einen Typenwechsel erzwingen:
as.character(dat1$profs) ## die "" zeigen an, dass die Variable als character definiert ist[1] "322" "67" "210"Das ändert erstmal nichts an der Ausgangsvariable dat1$profs:
class(dat1$profs)[1] "numeric"Wenn wir diese Umwandlung für dat1$profs behalten wollen, dann müssen wir die Variable überschreiben:
dat1$profs <- as.character(dat1$profs)
dat1$profs [1] "322" "67" "210"class(dat1$profs)[1] "character"Mit character-Variablen kann nicht gerechnet werden, auch wenn sie Zahlen enthalten:
dat1$profs / 2 Error in dat1$profs/2: nicht-numerisches Argument für binären OperatorWir können aber natürlich dat1$profs spontan mit as.numeric umwandeln, um mit den Zahlenwerten zu rechnen:
as.numeric(dat1$profs)[1] 322 67 210as.numeric(dat1$profs) / 2[1] 161.0 33.5 105.0Wenn wir Textvariablen in numerische Variablen umwandeln, bekommen wir NAs ausgegeben. NA steht in R für fehlende Werte:
as.numeric(dat1$uni)Warning: NAs durch Umwandlung erzeugt[1] NA NA NAR weiß (verständlicherweise) also nicht, wie die Uni-Namen in Zahlen umgewandelt werden sollen.
Tip
Nicht selten ist ein Problem bei einer Berechnung auf den falschen Variablentypen zurückzuführen.
2.2.1 Übung
2.3 Pakete in R
Im nächsten Schritt möchten wir jetzt nur einige Zeilen (Fälle) und/oder Spalten (Variablen) auswählen. Dazu verwenden wir das Paket {dplyr}2.
Pakete sind Erweiterungen für R, die zusätzliche Funktionen beinhalten. Pakete müssen einmalig installiert werden und dann vor der Verwendung in einer neuen Session (also nach jedem Neustart von R/RStudio) geladen werden. install.packages() leistet die Installation, mit library() werden die Pakete geladen:
install.packages("Paket") # auf eurem PC nur einmal nötig
library(Paket) # nach jedem Neustart nötigHäufig werden bei install.packages() nicht nur das angegebene Paket, sondern auch eine Reihe weiterer Pakete heruntergeladen, die sog. “dependencies”. Das sind Pakete, welche im Hintergrund verwendet werden, um die Funktionen des eigentlich gewünschten Pakets zu ermöglichen. Also nicht erschrecken, wenn die Installation etwas umfangreicher ausfällt.
Mit install.packages() schrauben wir sozusagen die Glühbirne in R, mit library() betätigen wir den Lichtschalter, sodass wir die Befehle aus dem Paket auch verwenden können. Mit jedem Neustart geht die Glühbirne wieder aus und wir müssen sie mit library() wieder aktivieren. Das hat aber den Vorteil, dass wir nicht alle Glühbirnen auf einmal anknipsen müssen, wenn wir R starten.

install.packages() im BIBB-Netzwerk
Aufgrund der VPN-Einstellungen im BIBB muss in R folgende Option gesetzt werden, damit Downloads möglich sind:
options(download.file.method = "wininet")
Dazu bieten sich zwei Möglichkeiten:
- nach jedem Neustart von RStudio vor
install.packages()mit setzen:
options(download.file.method = "wininet")
install.packages()- diese Option permanent “verankern”: wer den Befehl nicht zu Beginn jeden R-Scripts aufführen möchte, kann ihn in die
Rprofile-Datei (Rprofile.site) mit globalen Einstellungen aufnehmen. Diese Datei liegt beim BIBB Arbeitsgerät unter folgendem Pfad:C:\RforWindows_4_2_1\etcMehr zu RProfile
Pakete einmalig laden
Neben library() gibt es auch die Möglichkeit, Funktionen aus Paketen mit :: aufzurufen:
paket::function()Diese Option wird häufig verwendet, wenn lediglich eine Funktion aus einem Paket einmalig verwendet wird und oder um deutlich zu machen, aus welchem Paket die verwendete Funktion kommt. Das kann auch bei Problemen mit einem Befehl hilfreich sein: evtl. wurde ein weiteres Paket mit einem gleichnamigen Befehl geladen - dann wird der erste Befehl überschrieben (meist mit einer Warnung), die bespielweise so aussehen kann:
Die folgenden Objekte sind maskiert von ‘package:dplyr’:
between, first, last
Das folgende Objekt ist maskiert ‘package:purrr’:
transposeDas kann umgangen werden, wenn gewisse Pakte gar nicht vollständig geladen, sondern lediglich die nötigen Funktionen mit :: aufgerufen werden.
Wenn keine Internetverbindung besteht
Unter R Packages können die benötigten Pakete heruntergeladen werden. Nachdem wir das Paket als .zip-Datei gespeichert haben, wir mit folgendem Befehl das Paket in der R-Umgebung installieren:
# Installation von Paket "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")2.4 {tidyverse}
Wir werden in diesem Kurs vor allem mit Paketen aus dem {tidyverse} arbeiten. tidyverse ist eine Sammlung an Paketen, die übergreifende Syntaxlogik haben und so besonders gut miteinander harmonisieren und eine riesige Bandbreite an Anwendungsfällen abdecken. Mit
install.packages("tidyverse")werden folgende Pakete installiert:
broom, conflicted, cli, dbplyr, dplyr, dtplyr, forcats, ggplot2, googledrive, googlesheets4, haven, hms, httr, jsonlite, lubridate, magrittr, modelr, pillar, purrr, ragg, readr, readxl, reprex, rlang, rstudioapi, rvest, stringr, tibble, tidyr, xml2, tidyverse
Wir werden einige im Laufe des Kurses kennen lernen. Das zunächst wichtigste ist {dplyr}, welches unter anderem die Auswahl von Fällen und Variablen erleichtert:
{dplyr} Cheatsheetinstall.packages("tidyverse")
# installiert die komplette Paketsammlung des tidyverse2.5 Zeilen auswählen mit slice()
library(tidyverse) # nach einmaligem install.packages("tidyverse")Eine erste Funktion aus dem {tidyverse} ist slice(), mit welcher wir Zeilen auswählen können:
slice(dat1,1) studs profs gegr stu_prof uni
1 19173 322 1971 59.54348 Uni Bremen2:3 # ergibt eine Zahlenfolge[1] 2 3slice(dat1,2:3) studs profs gegr stu_prof uni
1 5333 67 1830 79.59701 Uni Vechta
2 15643 210 1973 74.49048 Uni Oldenburgc(1,3) # Vektor mit Werten[1] 1 3slice(dat1,c(1,3)) studs profs gegr stu_prof uni
1 19173 322 1971 59.54348 Uni Bremen
2 15643 210 1973 74.49048 Uni Oldenburg2.6 Beobachtungen auswählen mit filter()
Nachdem wir zunächst das Paket für filter() installiert haben (das ist {dplyr}) müssen wir das Paket noch mit library() laden:
filter(dat1,uni == "Uni Oldenburg", studs > 1000) studs profs gegr stu_prof uni
1 15643 210 1973 74.49048 Uni OldenburgDie Auswahl ändert das Ausgangsobjekt dat1 aber nicht:
dat1 studs profs gegr stu_prof uni
1 19173 322 1971 59.54348 Uni Bremen
2 5333 67 1830 79.59701 Uni Vechta
3 15643 210 1973 74.49048 Uni OldenburgMöchten wir das Ergebnis unserer Auswahl mit filter() für weitere Schritte behalten, können wir unser Ergebnis in einem neuen data.frame-Objekt ablegen:
ueber_10tsd <- filter(dat1, studs > 10000)
ueber_10tsd studs profs gegr stu_prof uni
1 19173 322 1971 59.54348 Uni Bremen
2 15643 210 1973 74.49048 Uni Oldenburgclass(ueber_10tsd)[1] "data.frame"2.6.1 Auswahloperatoren
R und {dplyr} stellen uns einige weitere Operatoren zur Auswahl von Zeilen zu Verfügung:
<=und>=|oder%in%“eines von”between()ist eine Hilfsfunktion aus{dplyr}für Wertebereiche
filter(dat1, studs >= 10000)
filter(dat1, studs <= 10000)
filter(dat1,studs > 10000 | profs < 200) # mehr als 10.000 Studierende *oder* weniger als 200 Professuren
filter(dat1, gegr %in% c(1971,1830)) # gegründet 1971 oder 1830
filter(dat1, between(gegr,1971,1830)) # gegründet zwischen 1971 und 1830 (einschließlich)2.7 Variablentypen II: logical
Diese Auswahl basiert auf einem dritten Variablentyp: ‘logical’, also logische Werte mit TRUE oder FALSE. Wenn wir mit ==, > oder < eine Bedingung formulieren, dann erstellen wir eigentlich einen logischen Vektor in der selben Länge wie die Daten:
dat1$studs > 10000 # ist die Studi-Zahl größer 10000?[1] TRUE FALSE TRUEdat1$more10k <- dat1$studs > 10000 # ist die Studi-Zahl größer 10000?dat1 studs profs gegr stu_prof uni more10k
1 19173 322 1971 59.54348 Uni Bremen TRUE
2 5333 67 1830 79.59701 Uni Vechta FALSE
3 15643 210 1973 74.49048 Uni Oldenburg TRUEWir könnten dann auch auf Basis dieser Variable filtern:
filter(dat1,more10k) studs profs gegr stu_prof uni more10k
1 19173 322 1971 59.54348 Uni Bremen TRUE
2 15643 210 1973 74.49048 Uni Oldenburg TRUE2.8 Variablen auswählen mit select()
Mit select() enthält {dplyr} auch einen Befehl zu Auswahl von Spalten/Variablen:
dat1 studs profs gegr stu_prof uni more10k
1 19173 322 1971 59.54348 Uni Bremen TRUE
2 5333 67 1830 79.59701 Uni Vechta FALSE
3 15643 210 1973 74.49048 Uni Oldenburg TRUEselect(dat1, studs,profs) studs profs
1 19173 322
2 5333 67
3 15643 210Wir können auch hier einige Operatoren verwenden: : um einen Bereich auszuwählen oder ! als “nicht”-Operator:
select(dat1, 1:3) # Spalte 1-3 studs profs gegr
1 19173 322 1971
2 5333 67 1830
3 15643 210 1973select(dat1, !profs) # alles außer profs studs gegr stu_prof uni more10k
1 19173 1971 59.54348 Uni Bremen TRUE
2 5333 1830 79.59701 Uni Vechta FALSE
3 15643 1973 74.49048 Uni Oldenburg TRUEAuch hier gilt: wenn wir die Veränderungen auch weiter verwenden wollen, müssen wir sie in einem neuen Objekt ablegen:
dat_ohne_profs <- select(dat1, !profs)
dat_ohne_profs studs gegr stu_prof uni more10k
1 19173 1971 59.54348 Uni Bremen TRUE
2 5333 1830 79.59701 Uni Vechta FALSE
3 15643 1973 74.49048 Uni Oldenburg TRUE…oder das alte überschreiben:
dat1 <- select(dat1, !profs) # alles außer profs2.8.1 Hilfsfunktionen
select() hat außerdem einige Hilfsfunktionen, welche die Variablenauswahl auf Basis der Variablennamen einfacher machen.
starts_with(): Variablenname beginnt mit …, bspw.select(dat1,starts_with("p"))ends_with(): Variablenname endet mit …, bspw.select(dat1,ends_with("p"))matches(): Variablenauswahl mit einer regular expression, bspw.select(dat1,matches("_")): alle Variablen mit_im Namen.num_range(): Variablen mit Zahlenbereiche:select(etb,num_range("F",1:220))last_col(): Letzte Variable, für die 4.letzte Variable bspw.last_col(4)any_of()um eine Auswahl auf Basis einescharacter-Vektors zu treffen
Code
# Spalten eines `data.frame`s auf Basis der `colnames` eines data.frames auswählen möchten:
col_auswahl <- colnames(dat1_orig)
col_auswahl
select(dat1, any_of(col_auswahl) )
# Oder wir wollen alle Variablen, die mit "s" beginnen:
select(dat1,starts_with("s"))
select(dat1,matches("^s")) # gleiches Ergebnis mit regex
select(dat1,matches("s$")) # alle Spalten, die mit s endenEs gibt noch einige weitere Hilfsfunktionen, für eine vollständige Auflistung ?select_helpers.
2.8.2 Übung
2.9 Arbeiten mit der Pipe: filter() und select() kombinieren
Wenn wir jetzt aber einige Zeilen und einige Spalten auswählen möchten, dann können wir filter() und select() kombinieren:
select(filter(dat1,studs < 10000),uni) uni
1 Uni VechtaDiese Befehlsschachtel können wir mit der sog. Pipe %>% auflösen. %>% steht einfach für “und dann”. Die Pipe kommt aus dem Paket {magrittr}, welches wiederum Teil des tidyverse ist und automatisch mit {dplyr} geladen wird.
filter(dat1,studs < 10000) %>% select(uni) uni
1 Uni VechtaHäufig wird die Pipe dann so verwendet, dass zu Beginn lediglich der zu bearbeitende Datensatz steht und sich dann die Schritte anschließen:
dat1 %>% filter(.,studs < 10000) %>% select(.,uni) uni
1 Uni VechtaDer Punkt . steht jeweils für das Ergebnis des vorherigen Schritts. Hier also:
- Rufe
dat1auf und dann (%>%) - Wähle nur Zeilen aus in denen
studs< 10000 und dann (%>%) - Behalte nur die Spalte
uni
Dan Punkt können wir auch weglassen:
dat1 %>% filter(studs < 10000) %>% select(uni) uni
1 Uni Vechta
Tip
%>% kann mit STRG+SHIFT+m (cmd+shift+m für Mac) eingefügt werden.
2.10 Variablentyp III: factor - eigene Reihenfolgen festlegen
Ein weitere häufige Aufgabe in der Datenanalyse ist das Sortieren von Datensätzen. Dazu haben wir arrange() zur Verfügung:
dat1 %>% arrange(studs) studs profs gegr stu_prof uni more10k
1 5333 67 1830 79.59701 Uni Vechta FALSE
2 15643 210 1973 74.49048 Uni Oldenburg TRUE
3 19173 322 1971 59.54348 Uni Bremen TRUEDas funktioniert auch für string-Variablen:
dat1 %>% arrange(uni) studs profs gegr stu_prof uni more10k
1 19173 322 1971 59.54348 Uni Bremen TRUE
2 15643 210 1973 74.49048 Uni Oldenburg TRUE
3 5333 67 1830 79.59701 Uni Vechta FALSEWas aber, wenn wir eine fixe Ordnung vergeben möchten, die nicht der numerischen oder alphabetischen Ordnung entspricht? Hier bspw. wenn wir die Unis in folgende Ordnung bringen möchten: 1) Uni Oldenburg, 2) Uni Bremen und 3) Uni Vechta. Dabei hilft uns ein dritter Variablentyp: factor.
Mit dem Argument levels = können wir eine Reihenfolge festlegen:
factor(dat1$uni, levels = c("Uni Oldenburg", "Uni Bremen", "Uni Vechta"))[1] Uni Bremen Uni Vechta Uni Oldenburg
Levels: Uni Oldenburg Uni Bremen Uni Vechtadat1$uni_fct <- factor(dat1$uni,
levels = c("Uni Oldenburg", "Uni Bremen", "Uni Vechta"))Wenn wir nun nach uni_fct sortieren, dann wird die Reihenfolge der levels berücksichtigt:
class(dat1$uni_fct)[1] "factor"dat1 %>% arrange(uni_fct) studs profs gegr stu_prof uni more10k uni_fct
1 15643 210 1973 74.49048 Uni Oldenburg TRUE Uni Oldenburg
2 19173 322 1971 59.54348 Uni Bremen TRUE Uni Bremen
3 5333 67 1830 79.59701 Uni Vechta FALSE Uni VechtaMit desc() können wir in umgekehrter Reihenfolge sortieren:
dat1 %>% arrange(desc(uni_fct)) studs profs gegr stu_prof uni more10k uni_fct
1 5333 67 1830 79.59701 Uni Vechta FALSE Uni Vechta
2 19173 322 1971 59.54348 Uni Bremen TRUE Uni Bremen
3 15643 210 1973 74.49048 Uni Oldenburg TRUE Uni OldenburgDas mag für den Moment relativ trivial erscheinen, ist aber später sehr praktisch um in Grafiken Variablen in eine gewisse Ordnung zu bringen oder in Regressionsmodellen die Referenzkategorie festzulegen.
Natürlich können wir auch nach mehreren Variablen sortieren, dazu fügen wir einfach weitere in arrange() ein:
dat1 %>% arrange(desc(uni_fct), gegr, studs) studs profs gegr stu_prof uni more10k uni_fct
1 5333 67 1830 79.59701 Uni Vechta FALSE Uni Vechta
2 19173 322 1971 59.54348 Uni Bremen TRUE Uni Bremen
3 15643 210 1973 74.49048 Uni Oldenburg TRUE Uni Oldenburg(Macht in diesem Beispiel aber wenig Sinn)
2.10.1 Übung
2.11 Datensätze einlesen
In der Regel werden wir aber Datensätze verwenden, deren Werte bereits in einer Datei gespeichert sind und die wir lediglich einlesen müssen. Dafür gibt es unzählige Möglichkeiten.
Wir werden hier vor allem den Import von csv-Dateien verwenden. csv 3 bezeichnet ein verbreitetes Dateiformat zur Speicherung oder zum Austausch einfach strukturierter Daten. Wesentlich für unsere Zwecke hier ist, dass in csv-Dateien die Spalten eines Datensatzes mit einem Trennzeichen gekennzeichnet sind. Verbreitete Trennzeichen sind Komma, Doppelpunkt oder Semikolon. Für alle weiteren Dateien, die wir im Lauf dieser Veranstaltung verwenden werden, ist das Semikolon als Trennzeichen gesetzt. Unser Datensatz dat1 sieht im csv-Format so aus:
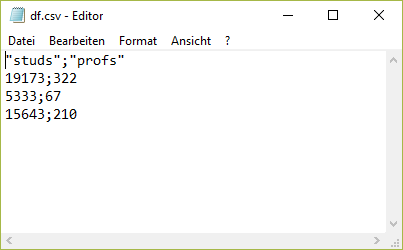
In diesem Seminar werden wir mit Daten aus BIBB/BAuA-Erwerbstätigenbefragung 2018 arbeiten. Die BIBB/BAuA ist eine Repräsentativbefragung von in Deutschland zu Arbeit und Beruf im Wandel und Erwerb und Verwertung beruflicher Qualifikation. Nun wollen wir also eine csv-Datei einlesen, zunächst eine reduzierte Version der ETB 2018.
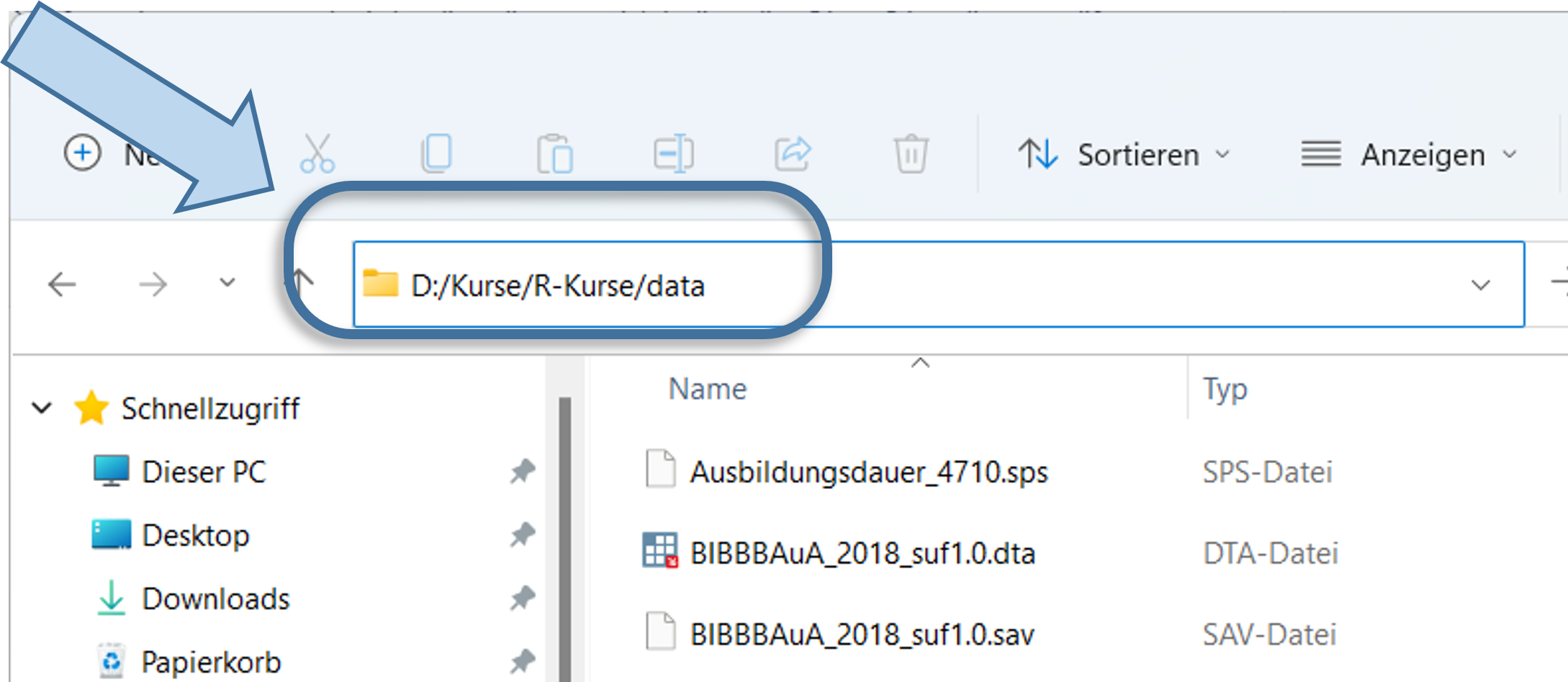
Um den Datensatz nun in R zu importieren, müssen wir R mitteilen unter welchem Dateipfad der Datensatz zu finden ist. Der Dateipfad ergibt sich aus der Ordnerstruktur Ihres Gerätes, so würde der Dateipfad im hier dargestellten Fall “D:/Kurse/R-Kurs/” lauten:
Natürlich hängt der Dateipfad aber ganz davon ab, wo Sie den Datensatz gespeichert haben:
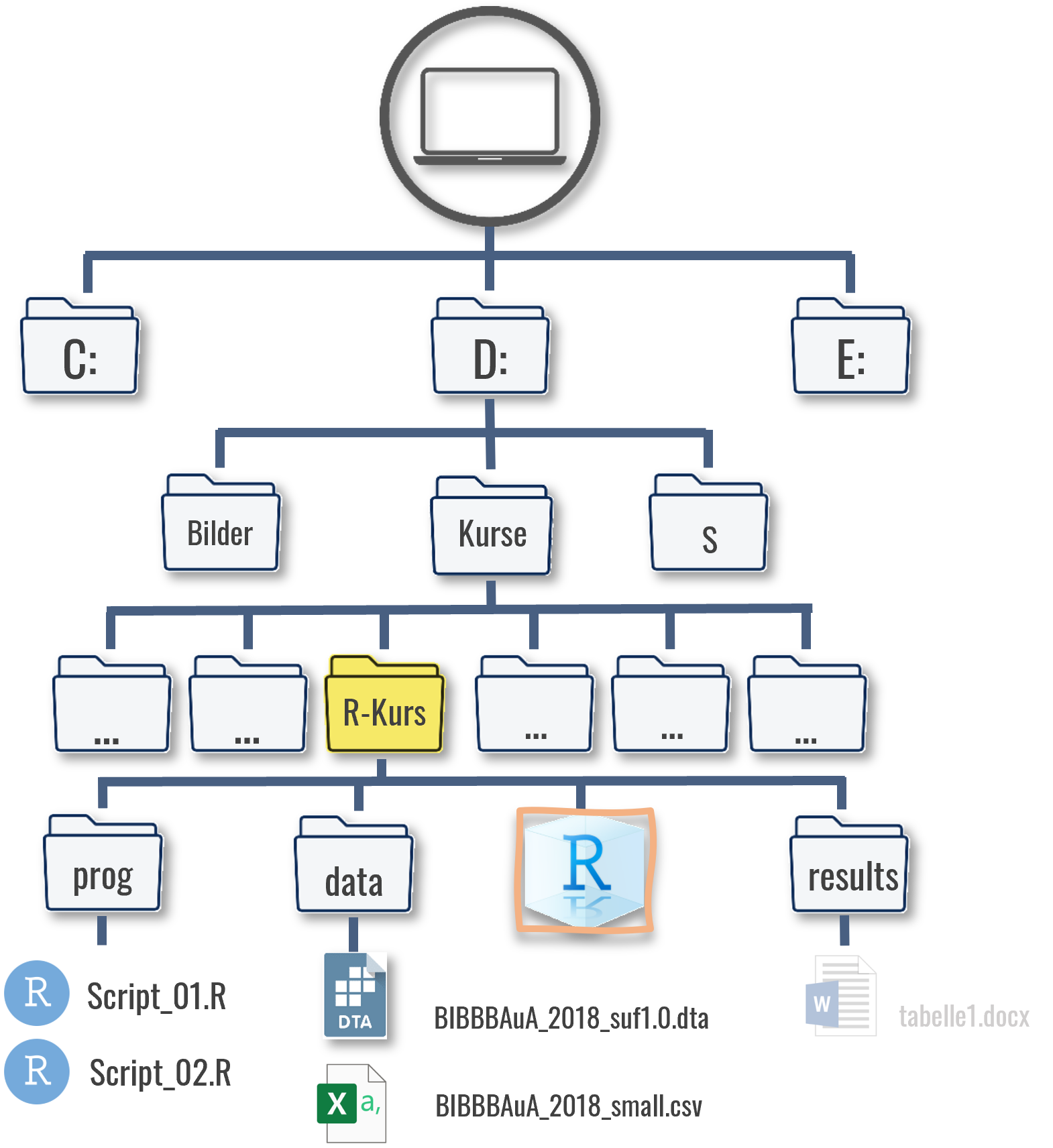
Um den Pfad des Ordners herauszufinden, klicken Sie bei Windows in die obere Adresszeile im Explorerfenster.
In iOS (Mac) finden Sie den Pfad, indem Sie einmal mit der rechten Maustaste auf die Datei klicken und dann die ALT-Taste gedrückt halten. Dann sollte die Option “…als Pfadname kopieren” erscheinen. Youtube Anleitung
Diesen Dateipfad müssen wir also R mitteilen.
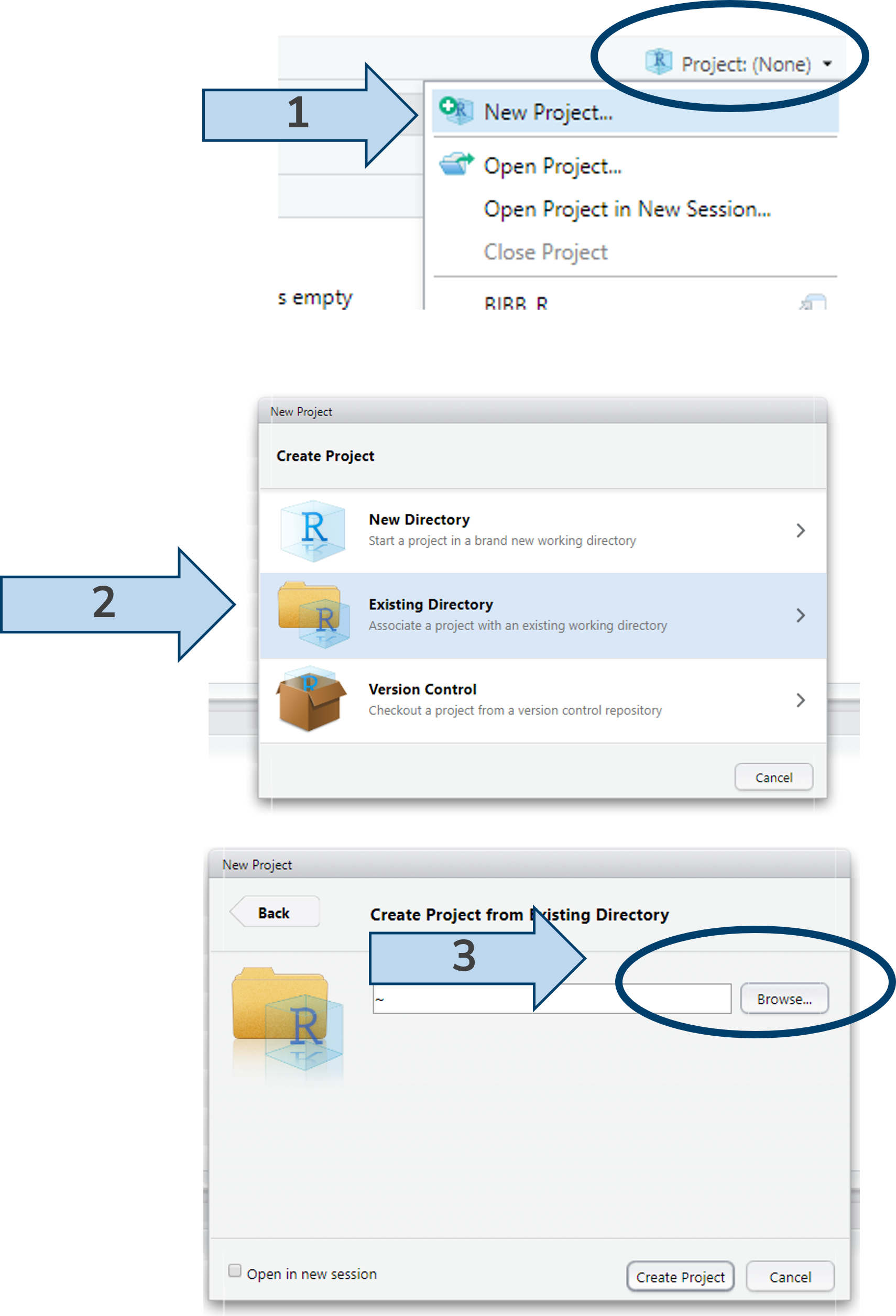
2.11.1 Projekt einrichten
Grundsätzlich lohnt es sich, in RStudio Projekte einzurichten. Projekte sind .Rproj-Dateien ![]() , die automatisch Arbeitsverzeichnis auf den Ort setzen, an dem sie gespeichert sind. Das erleichtert das kollaborative Arbeiten: egal wer und auf welchem Gerät gerade an einem Projekt arbeitet - durch die Projektdatei sind alle Pfade immer relativ zum Projektverzeichnis. Im weiteren können auch Versionkontrolle via git, bspw. github und weitere Funktionen in der Projektdatei hinterlegt werden und so für alle Nutzenden gleich gesetzt werden. Außerdem bleiben die zuletzt geöffneten Scripte geöffnet, was ein Arbeiten an mehreren Projekten erleichtert.
, die automatisch Arbeitsverzeichnis auf den Ort setzen, an dem sie gespeichert sind. Das erleichtert das kollaborative Arbeiten: egal wer und auf welchem Gerät gerade an einem Projekt arbeitet - durch die Projektdatei sind alle Pfade immer relativ zum Projektverzeichnis. Im weiteren können auch Versionkontrolle via git, bspw. github und weitere Funktionen in der Projektdatei hinterlegt werden und so für alle Nutzenden gleich gesetzt werden. Außerdem bleiben die zuletzt geöffneten Scripte geöffnet, was ein Arbeiten an mehreren Projekten erleichtert.
Mit getwd() lässt sich überprüfen, ob das funktioniert hat:
getwd()[1] "D:/Kurse/R-Kurs"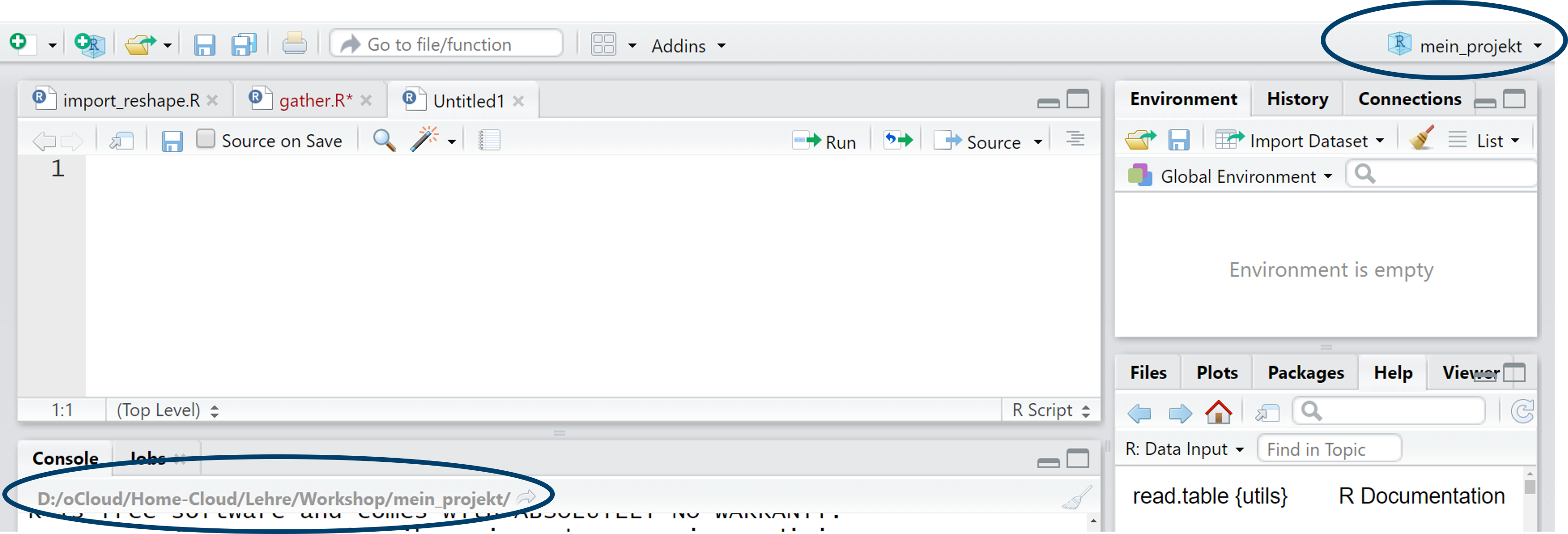
Alternativ könnten wir auch mit folgendem Befehl ein .Rproj - Projekt erstellen (hier ein Beispiel für den Aufruf eines Pakets mit ::):
rstudioapi::initializeProject(path = "D:/Kurse/R-Kurs")2.11.2 Der Einlesebefehl
Jetzt können wir den eigentlichen Einlesebefehl read.table verwenden. Für den Pfad können wir nach file = lediglich die Anführungszeichen angeben und innerhalb dieser die Tab-Taste drücken. Dann bekommen wir alle Unterverzeichnisse und Tabellen im Projektordner angezeigt.4
etb <- read.table(file = "./data/BIBBBAuA_2018_small.csv", sep = ";", header = T)Der Einlesevorgang besteht aus zwei Teilen: zuerst geben wir mit etb den Objektnamen an, unter dem R den Datensatz ablegt. Nach dem <- steht dann der eigentliche Befehl read.table(), der wiederum mehrere Optionen enthält. Als erstes geben wir den genauen Datensatznamen an - inklusive der Dateiendung. Darüber hinaus teilen wir R mit sep mit, dass ; als Trennzeichen gesetzt wurde und mit header = T (T steht für TRUE) teilen wir R zudem mit, dass die erste Zeile aus dem Datensatz als Spaltennamen verwendet werden soll.
Leider nutzen Windows-Systeme \ in den Dateipfaden - das führt in R zu Problemen. Daher müssen Dateipfade immer mit / oder alternativ mit \\ angegeben werden. RStudio kann zumindest etwas unterstützen, dem mit der STRG + F die Suchen & Ersetzen Funktion verwendet wird.
Würden hier jetzt einfach etb eintippen bekämen wir den kompletten Datensatz angezeigt. Für einen Überblick können wir head verwenden:
head(etb) intnr az S1 S3 S2_j zpalter Stib Bula m1202 F209 F209_01
1 260 80 1 8 1976 41 4 11 4 1 NA
2 361 30 2 5 1966 51 2 11 2 1 NA
3 491 40 1 7 1968 49 1 11 4 2 1
4 690 40 2 8 1954 63 3 11 4 1 NA
5 919 39 2 7 1976 41 2 11 2 1 NA
6 1041 40 1 5 1960 57 2 11 2 2 2Mit nrow und ncol können wir kontrollieren, ob das geklappt hat. Der Datensatz sollte 20012 Zeilen und 11 Spalten haben:
nrow(etb)[1] 20012ncol(etb)[1] 11Natürlich können wir wie oben auch aus diesem, viel größeren, Datensatz Zeilen und Spalten auswählen. Zum Beispiel können wir die Befragten auswählen, die vor 1940 geboren sind und diese unter senior ablegen:
senior <- etb %>% filter(S2_j < 1940)Möchten wir die genauen Altersangaben der Befragten aus senior sehen, können wir die entsprechende Spalte mit senior$age aufrufen:
senior$zpalter [1] 78 83 78 81 81 78 81 80 82 81 79 79 81 78 87Außerdem hat senior natürlich deutlich weniger Zeilen als etb:
nrow(senior)[1] 15Wie wir beim Überblick gesehen haben, gibt es aber noch deutlich mehr Variablen in der ETB als zpalter und nicht alle haben so aussagekräftige Namen - z.B. gkpol. Um diese Variablennamen und auch die Bedeutung der Ausprägungen zu verstehen brauchen wir das Codebuch. Außerdem können wir auf die attributes() einer Variable zurückgreifen - mehr zu labels später.
2.11.3 Übung
2.12 Überblick: Einlesen und Exportieren
2.12.1 Datensätze einlesen
| Dateityp | R Funktion | R Paket | Anmerkung |
|---|---|---|---|
| .csv | read.table() | - | mit `sep = ";"` Trennzeichen angeben |
| .Rdata (R format) | readRDS | - | |
| große .csv | vroom() | {vroom} | mit `delim = ";"` Trennzeichen angeben |
| .dta (Stata) | read_dta() | {haven} | |
| .dat (SPSS) | read_spss() | {haven} | |
| .xlsx (Excel) | read_xlsx() | {readxl} | mit `sheet = 1` Tabellenblatt angeben (funktioniert auch mit Namen) |
# csv Datei
dat1 <- read.table(file = "Dateiname.csv",sep = ";")
# Rdata
dat1 <- readRDS(file = "Dateiname.Rdata")
# große csv
library(vroom)
dat1 <- vroom(file = "Dateiname.csv",delim = ";")
# Stata dta
library(haven)
dat1 <- read_dta(file = "Dateiname.dta")
# SPSS sav
dat1 <- read_sav(file = "Dateiname.sav")
# Excel
dat1 <- read_xlsx(path = "Dateiname.xlsx", sheet = "1")
dat1 <- read_xlsx(path = "Dateiname.xlsx", sheet = "Tabellenblatt1")2.12.2 Datensätze exportieren
| Dateityp | R Funktion | R Paket | Anmerkung |
|---|---|---|---|
| .Rdata (R format) | saveRDS() | - | alle Variableneigenschaften bleiben erhalten |
| .csv | write.table() | - | mit `sep = ";"` Trennzeichen angeben mit row.names= F Zeilennummerierung unterdrücken |
| .dta (Stata) | write_dta() | {haven} | |
| .dat (SPSS) | write_spss() | {haven} | |
| .xlsx (Excel) | write.xlsx() | {xlsx} | mit `sheetName` ggf. Tabellenblattname angeben |
# Rdata
saveRDS(dat1,file = "Dateiname.Rdata")
# csv
write.table(dat1,file = "Dateiname.csv",sep = ";",row.names = F)
# dta
library(haven)
write_dta(dat1,path = "Dateiname.dta")
# sav
library(haven)
write_sav(dat1,path = "Dateiname.sav")
# xlsx
library(xlsx)
write.xlsx(dat1,file = "Dateiname.xlsx", sheetName = "Tabellenblatt 1")2.12.3 Objekte exportieren
Wir können aber auch einzelne oder mehrere Objekte exportieren und später wieder einlesen:
save(studs, file = "./data/stud_vektor.RData")
rm(studs)
load(file = "./data/stud_vektor.RData") # studs wieder mit selbem Namen zurück im environmentMehrere Objekte:
save(studs,profs, file = "./data/meine_vektoren.RData")
rm(studs,profs)
load(file = "./data/meine_vektoren.RData") # studs & profs mit selbem Namen zurück im environmentDer Begriff speichern kann in R bisweilen zu Missverständnissen führen: Ist gemeint, einen Datensatz o.ä. (1) auf der Festplatte als .csv, .dta, .sav für andere Programme zugänglich abzulegen oder lediglich die Ergebnisse intern in R unter einem Objektnamen abzulegen? Ich vermeide daher das Wort speichern und spreche entweder von exportieren (im Fall 1 - in eine Datei schreiben) oder ablegen (Fall 2 - Ergebnisse/Werte innerhalb von R in einem Objekt abzulegen)
2.13 Hilfe zu Paketen und Funktionen
R Pakete kommen (häufig) mit sehr ausführlichen Hilfeseiten, die entweder direkt aus RStudio abgerufen werden können:
# Hilfe zu Paketen
vignette("dplyr")
vignette(package = "dplyr")
vignette("rowwise")
help("dplyr")
help(package = "dplyr")
# Hilfe zu Funktionen
?select()Alternativ führt aber Google auch zum Ziel, bspw. R dplyr select()
Oder auf CRAN (woher auch install.packages() die Pakete bezieht):
2.14 Übungen
2.14.1 Übung 1
- Erstellen Sie den Datensatz mit den Studierenden- & Prof-Zahlen wie gezeigt:
dat2 <- data.frame(studs = c(14954,47269 ,23659,9415 ,38079),
profs = c(250,553,438 ,150,636),
prom_recht = c(FALSE,TRUE,TRUE,TRUE,FALSE),
gegr = c(1971,1870,1457,1818,1995))- Sehen Sie den
dat2in Ihrem Environment? - Lassen Sie sich
dat2in der Console ausgeben. - Fügen Sie die Namen der Unis als neue Spalte in den Datensatz ein. Diese sind in dieser Reihenfolge:
c("FH Aachen","RWTH Aachen","Uni Freiburg","Uni Bonn","FH Bonn-Rhein-Sieg")- Lassen Sie sich
dat2anzeigen - in der Console oder mitView() - Berechnen Sie das Verhältnis Studierende pro Professur und legen Sie die Ergebnisse in einer neuen Variable an. Sehen Sie sich das Ergebnis an.
2.14.2 Übung 2
Installieren Sie die Pakete des tidyverse mitinstall.packages("tidyverse")- Verwenden Sie wieder den
data.framedat2aus Übung 1 - Nutzen Sie
filter, um sich nur die Unis mit unter 10000 Studierenden anzeigen zu lassen. (Denken Sie daran,{tidyverse}zu installieren und mitlibrary()zu laden) - Lassen Sie sich nur die dritte Zeile von
dat2anzeigen. - Lassen Sie sich nur die Spalte
gegranzeigen. - Lassen Sie sich nur Zeilen der Hochschulen mit Promotionsrecht (
prom_recht) anzeigen.
2.14.3 Übung 3
- Verwenden Sie weiterhin den Datensatz aus Übung 1 & 2.
- Lassen Sie sich nur Hochschulen anzeigen, die 1971, 1457 oder 1995 gegründet wurden - und für diese Fälle nur den Namen und das Gründungsjahr.
- Sortieren Sie den Datensatz entsprechend dieser Reihenfolge. (Legen Sie dazu eine
factor-Variable an, welche die entsprechende Reihenfolge festlegt.)
c("RWTH Aachen","Uni Freiburg","Uni Bonn","FH Aachen","FH Bonn-Rhein-Sieg")2.14.4 Übung 4
- Erstellen Sie in Ihrem Verzeichnis für diesen Kurs ein R-Projekt
- Legen Sie die Erwerbstätigenbefragung in Ihrem Verzeichnis im Unterordner data ab.
- Lesen Sie den Datensatz
BIBBBAuA_2018_small.csvwie oben gezeigt in R ein und legen Sie den Datensatz unter dem Objektnamenetb_smallab. - Nutzen Sie
head()undView(), um sich einen Überblick über den Datensatz zu verschaffen. - Wie viele Befragte (Zeilen) enthält der Datensatz?
- Lassen Sie sich die Variablennamen von
etb_smallmitnames()anzeigen! - Wie können Sie sich die Zeile anzeigen lassen, welche den/die Befragte*n mit der
intnr2781 enthält? - Wie alt ist der/die Befragte mit der
intnr2781? - Erstellen Sie eine neue Variable mit dem Alter der Befragten im Jahr 2022! (Das Geburtsjahr ist in der Variable
S2_jabgelegt.) - Wählen Sie alle Befragten aus, die nach 1960 geboren wurden legen Sie diese Auswahl unter
nach_1960ab. - Wie viele Spalten hat
nach_1960? Wie viele Zeilen?
2.15 Anhang
2.15.1 Alternativen zu R-Projekten
Neben dem Einrichten eines Projekts können wir den Pfad auch mit setwd() setzen oder direkt in read.table() angeben. Das hat allerdings den Nachteil, dass diese Strategie nicht auf andere Rechner übertragbar ist: wenn jemand anderes die .Rproj-Datei öffnet, wird R automatisch die Pfade relativ zum Speicherort der Datei setzen. Das gilt auch wenn wir das Verzeichnis verschieben auf unserem Gerät - R wird automatisch das Arbeitsverzeichnis auf den neuen Speicherort setzen.
Zum Setzen des Arbeitsverzeichnis mit setwd() setzen wir in die Klammern den Pfad des Ordners ein. Wichtig dabei ist dass Sie ggf. alle \ durch /ersetzen müssen:
setwd("D:/Kurse/R_BIBB")Mit getwd() lässt sich überprüfen, ob das funktioniert hat:
getwd()Hier sollte der mit setwd() gesetzte Pfad erscheinen.
Alternativ können wir auch in read.table() den vollen Pfad angeben:
etb <- read.table("C:/Kurse/R_BIBB/data/BIBBBAuA_2018_small.csv", sep = ";", header = T, stringsAsFactors = F)2.15.2 Zeilen & Spaltenauswahl ohne {dplyr}
Natürlich kann auch base R (also R ohne Erweiterungen wie {dplyr} Datensätze filtern usw.), dazu wird [ ] verwendet:
dat1[1,1] # erste Zeile, erste Spalte[1] 19173dat1[1,] # erste Zeile, alle Spalten studs profs gegr stu_prof uni more10k uni_fct
1 19173 322 1971 59.54348 Uni Bremen TRUE Uni Bremendat1[,1] # alle Zeilen, erste Spalte (entspricht hier dat1$studs)[1] 19173 5333 15643dat1[,"studs"] # alle Zeilen, Spalte mit Namen studs -> achtung: ""[1] 19173 5333 15643Natürlich können wir auch mehrere Zeilen oder Spalten auswählen. Dafür müssen wir wieder auf c( ) zurückgreifen:
dat1[c(1,2),] ## 1. & 2. Zeile, alle Spalten
dat1[,c(1,3)] ## alle Zeilen, 1. & 3. Spalte (entspricht dat1$studs & dat1$stu_prof)
dat1[,c("studs","uni")] ## alle Zeilen, Spalten mit Namen studs und uniIn diese eckigen Klammern können wir auch Bedingungen schreiben, um so Auswahlen aus dat1 zu treffen.
dat1 # vollständiger Datensatz studs profs gegr stu_prof uni more10k uni_fct
1 19173 322 1971 59.54348 Uni Bremen TRUE Uni Bremen
2 5333 67 1830 79.59701 Uni Vechta FALSE Uni Vechta
3 15643 210 1973 74.49048 Uni Oldenburg TRUE Uni Oldenburgdat1[dat1$uni == "Uni Oldenburg", ] # Zeilen in denen uni gleich "Uni Oldenburg", alle Spalten studs profs gegr stu_prof uni more10k uni_fct
3 15643 210 1973 74.49048 Uni Oldenburg TRUE Uni Oldenburgdat1$studs[dat1$uni == "Uni Oldenburg" ] # Nur Studi-Zahl nachsehen: kein Komma [1] 15643Das funktioniert soweit wie gewünscht und wir können das Ganze jetzt erweitern:
dat1[dat1$uni == "Uni Oldenburg" & dat1$studs > 10000, ] # & bedeutet UNDWir können auch hier einen ODER-Operator verwenden:
dat1[dat1$uni == "Uni Oldenburg" | dat1$studs > 10000, ]2.15.3 select() vs $
Wenn wir mit select() eine spezifische Variable auswählen, wird trotzdem die Datenstruktur als data.frame() erhalten, während die Auswahl dat1$variablenname die Spalte als Vektor (also Wertereihe) ausgibt:
dat1$studs[1] 19173 5333 15643class(dat1$studs)[1] "numeric"dat1$studs/ 20[1] 958.65 266.65 782.15select() erhält die Werte als Spalte eines data.frame:
dat1 %>% select(studs) studs
1 19173
2 5333
3 15643dat1 %>% select(studs) %>% class()[1] "data.frame"dat1 %>% select(studs)/20 studs
1 958.65
2 266.65
3 782.15In vielen anderen Programmiersprachen ist auch von Bibliotheken/“libraries” die Rede.↩︎
Es hat sich in der R-Community etabliert, Pakete mit
{}zu schreiben um sie deutlicher von Funktionen zu unterscheiden. Ich folge in diesem Skript dieser Konvention.↩︎Abkürzung für comma-separated values↩︎
Manchmal kann der Datensatz aber nicht im Unterordner des Projekts liegen, dann kann natürlich auch der gesamte Pfad in
read.table()angegeben werden:etb <- read.table(file = "D:/Kurse/R-Kurs/data/BIBBBAuA_2018_small.csv", sep = ";", header = T)↩︎