11 Data Wrangling III
11.1 Datensätze verbinden
A mutating join allows you to combine variables from two tables. It first matches observations by their keys, then copies across variables from one table to the other.
R for Data Science: Mutating joins
Ein Überblick zu den wichtigsten Befehlen:1
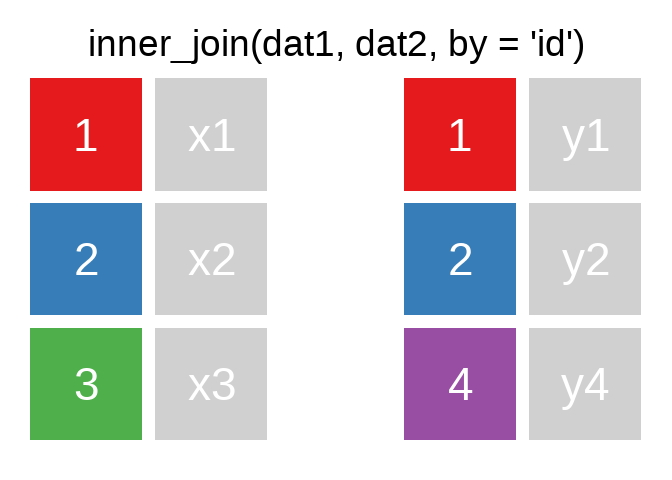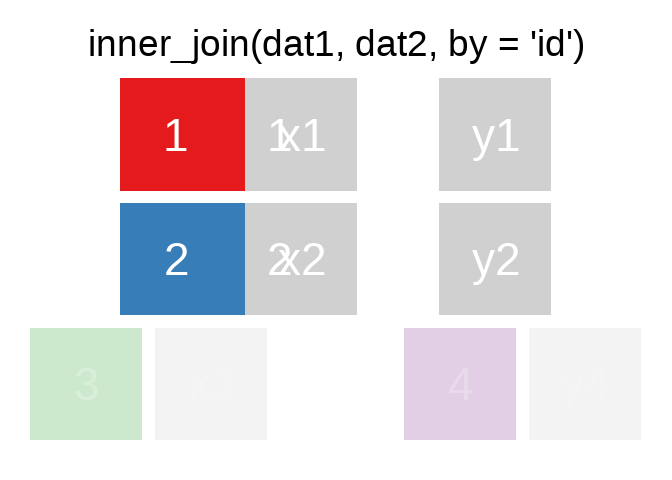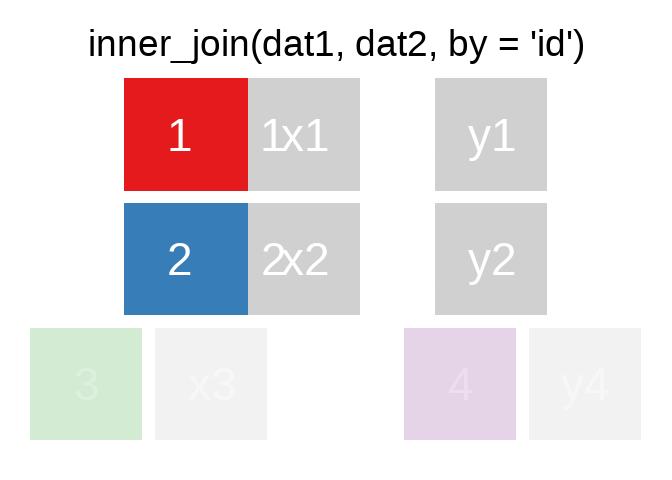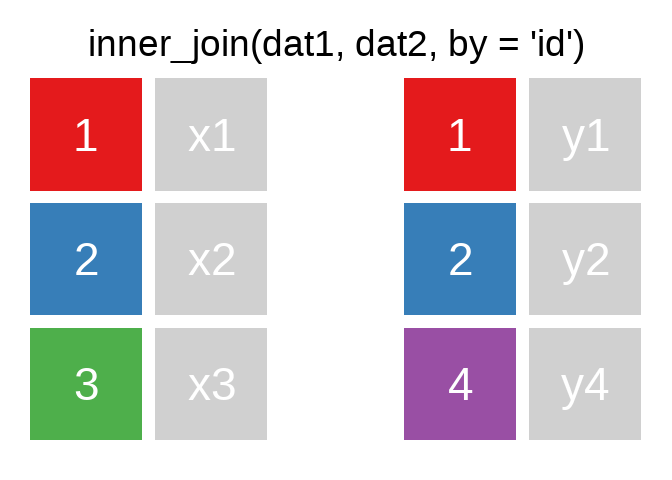
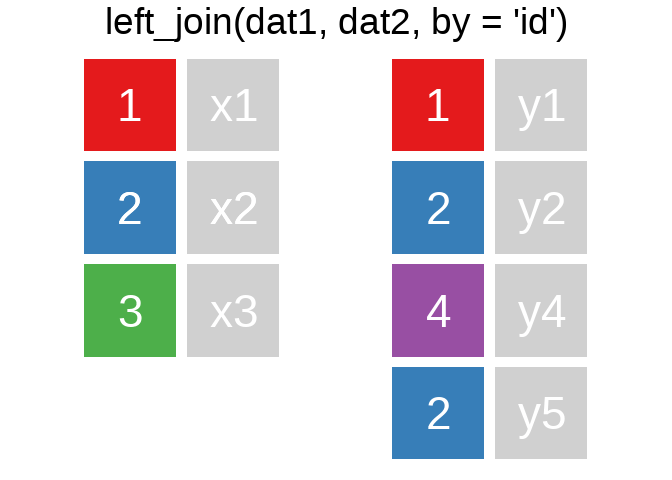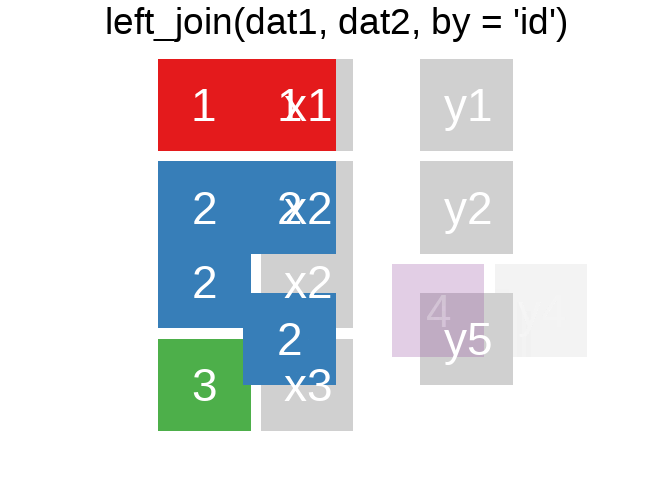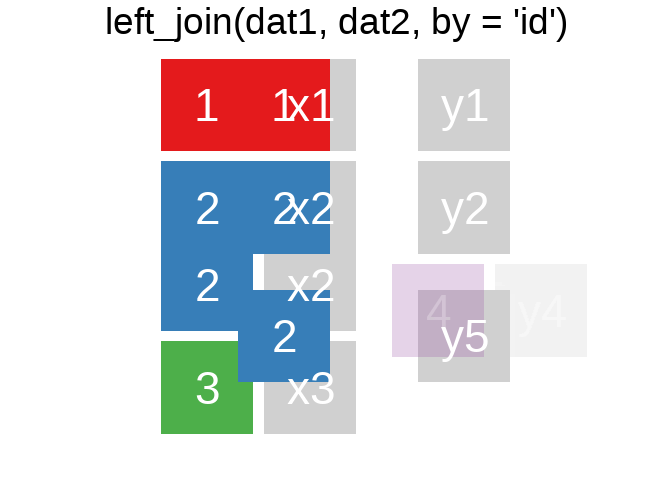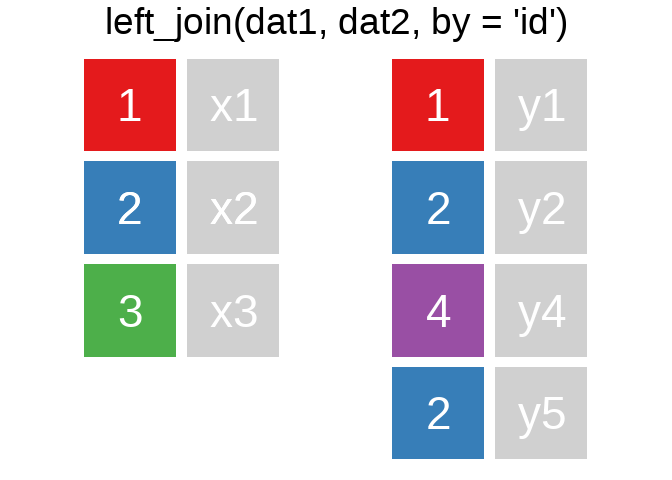
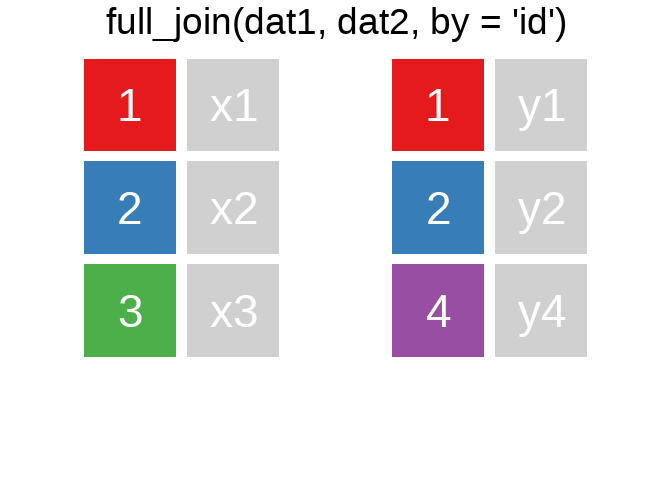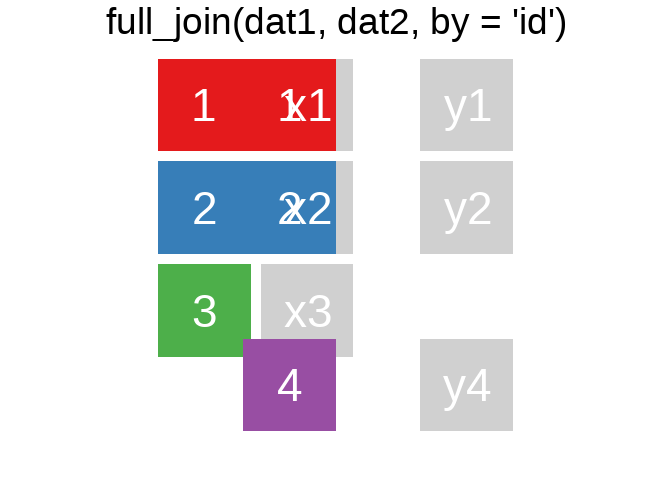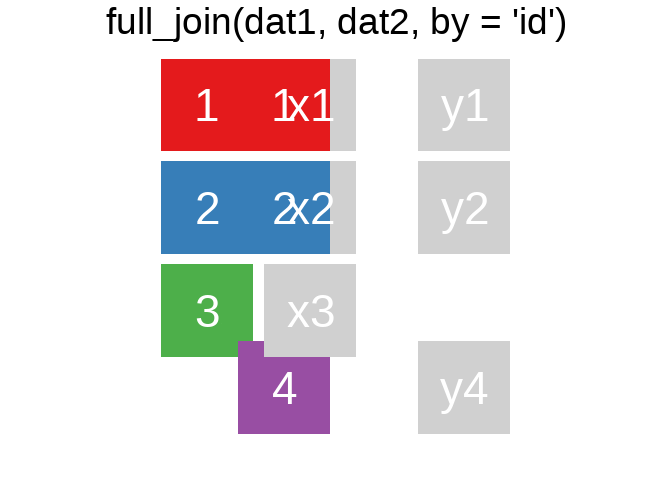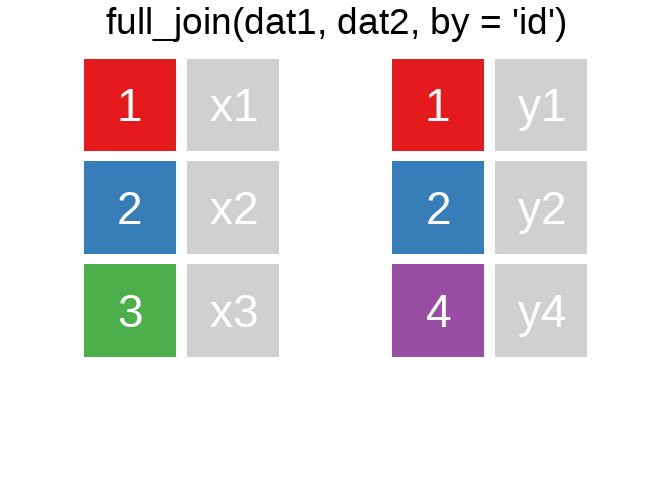
Es gibt natürlich auch right_join() oder anti_join(). Für eine tiefergehende Einführung lohnt sich das Kapitel Relational Data aus R for Data Science.
Eine sehr hilfreiche Option in den ..._join() ist die Verbindung unterschiedlicher Variablen. Bspw. haben wir hier einige Fälle aus der ETB18 und
Code
ids_df <- data.frame(pnr = sample(1:9,4),
Bula = c(2,1,14,15))
set.seed(90459)
alo_bula <- data.frame(bundesland = seq(1:8),
Werte = sample(letters,size = 8) # mit sample() kann eine zufällige Auswahl getroffen werden
)ids_df#> pnr Bula
#> 1 1 2
#> 2 4 1
#> 3 2 14
#> 4 5 15alo_bula#> bundesland Werte
#> 1 1 g
#> 2 2 m
#> 3 3 n
#> 4 4 z
#> 5 5 w
#> 6 6 r
#> 7 7 t
#> 8 8 hids_df %>% left_join(alo_bula,by = c("Bula"="bundesland"))#> pnr Bula Werte
#> 1 1 2 m
#> 2 4 1 g
#> 3 2 14 <NA>
#> 4 5 15 <NA>Ein sehr hilfreiche Checkmöglichkeit, die ich häufig verwende:
table(ids_df$Bula %in% alo_bula$bundesland)#>
#> FALSE TRUE
#> 2 211.1.1 Übung
11.2 Reshape: pivot_longer() & pivot_wider()
bsp_df <-
data.frame(
bula = c("NRW","NDS"),
alo2018 = c(2,2),
alo2017 = c(1,1)
)
bsp_df#> bula alo2018 alo2017
#> 1 NRW 2 1
#> 2 NDS 2 1Mit pivot_longer() können wir aus einem wide shape data.frame einen long shape machen:
bsp_df %>% pivot_longer(cols = c("alo2018","alo2017"),names_to = "year",values_to = "alo")#> # A tibble: 4 × 3
#> bula year alo
#> <chr> <chr> <dbl>
#> 1 NRW alo2018 2
#> 2 NRW alo2017 1
#> 3 NDS alo2018 2
#> 4 NDS alo2017 1Mit names_prefix = "alo" können wir das alo direkt löschen lassen:
bsp_df %>% pivot_longer(cols = c("alo2018","alo2017"),names_to = "year",values_to = "alo",names_prefix = "alo")#> # A tibble: 4 × 3
#> bula year alo
#> <chr> <chr> <dbl>
#> 1 NRW 2018 2
#> 2 NRW 2017 1
#> 3 NDS 2018 2
#> 4 NDS 2017 1Mit pivot_wider() können wir den umgekehrten Weg gehen:
bsp_df2 <-
data.frame(land = c("NRW","NDS","NRW","NDS"),
alo = c(2.1,1.8,2.4,2.2),
alter = c("age_1825","age_1825","age_2630","age_2630"))
bsp_df2#> land alo alter
#> 1 NRW 2.1 age_1825
#> 2 NDS 1.8 age_1825
#> 3 NRW 2.4 age_2630
#> 4 NDS 2.2 age_2630bsp_df2 %>% pivot_wider(names_from = alter,values_from = alo)#> # A tibble: 2 × 3
#> land age_1825 age_2630
#> <chr> <dbl> <dbl>
#> 1 NRW 2.1 2.4
#> 2 NDS 1.8 2.211.3 Übungen
11.3.1 Übung 1
Verknüpfen Sie die ausgewählten Beobachtungen des PASS CF mit der Haushalts-Information, in welcher Region (region) die Befragten wohnen. Mergen Sie dazu die region aus HHENDDAT_cf_W13.dta basierend auf der hnr und welle.
pend_ue11 <- haven::read_dta("./orig/PENDDAT_cf_W13.dta",
col_select = c("pnr","welle")) %>%
slice(1:10)
pend_ue11#> # A tibble: 10 × 2
#> pnr welle
#> <dbl> <dbl+lbl>
#> 1 1000001901 1 [Welle 1 (2006/2007)]
#> 2 1000001902 1 [Welle 1 (2006/2007)]
#> 3 1000001901 3 [Welle 3 (2008/2009)]
#> 4 1000002001 1 [Welle 1 (2006/2007)]
#> 5 1000002002 1 [Welle 1 (2006/2007)]
#> 6 1000002002 2 [Welle 2 (2007/2008)]
#> 7 1000002001 2 [Welle 2 (2007/2008)]
#> 8 1000002002 3 [Welle 3 (2008/2009)]
#> 9 1000002001 3 [Welle 3 (2008/2009)]
#> 10 1000002001 4 [Welle 4 (2010)]hh_dat <- haven::read_dta("./orig/HHENDDAT_cf_W13.dta", col_select = c("hnr","welle","region"))11.3.2 Übung 2
pend_ue11b <- haven::read_dta("./orig/PENDDAT_cf_W13.dta",
col_select = c("pnr","welle","famstand")) %>%
slice(200:210) %>%
filter(welle %in% 2:3)
pend_ue11b#> # A tibble: 6 × 3
#> pnr welle famstand
#> <dbl> <dbl+lbl> <dbl+lbl>
#> 1 1000014501 2 [Welle 2 (2007/2008)] -4 [Frage irrtuemlich nicht gestellt]
#> 2 1000014501 3 [Welle 3 (2008/2009)] 3 [Verheiratet/eing. Lebensp., getr. lebd…
#> 3 1000014701 2 [Welle 2 (2007/2008)] 2 [Verheiratet/eing. Lebensp., zus. lebd.]
#> 4 1000014702 2 [Welle 2 (2007/2008)] 2 [Verheiratet/eing. Lebensp., zus. lebd.]
#> 5 1000014702 3 [Welle 3 (2008/2009)] 2 [Verheiratet/eing. Lebensp., zus. lebd.]
#> 6 1000014701 3 [Welle 3 (2008/2009)] 2 [Verheiratet/eing. Lebensp., zus. lebd.]Bringen Sie pend_ue11b in das long shape:
#> # A tibble: 3 × 3
#> pnr `2` `3`
#> <dbl> <dbl+lbl> <dbl+lbl>
#> 1 1000014501 -4 [Frage irrtuemlich nicht gestellt] 3 [Verheiratet/eing. L…
#> 2 1000014701 2 [Verheiratet/eing. Lebensp., zus. lebd.] 2 [Verheiratet/eing. L…
#> 3 1000014702 2 [Verheiratet/eing. Lebensp., zus. lebd.] 2 [Verheiratet/eing. L…Tipp: mit ,names_prefix = "wave" in pivot_wider() können wir ein Präfix angeben:
#> # A tibble: 3 × 3
#> pnr wave2 wave3
#> <dbl> <dbl+lbl> <dbl+lbl>
#> 1 1000014501 -4 [Frage irrtuemlich nicht gestellt] 3 [Verheiratet/eing. L…
#> 2 1000014701 2 [Verheiratet/eing. Lebensp., zus. lebd.] 2 [Verheiratet/eing. L…
#> 3 1000014702 2 [Verheiratet/eing. Lebensp., zus. lebd.] 2 [Verheiratet/eing. L…Illustrationen mit tidyexplain↩︎